
思杰虚拟应用程序和桌面-
概要
このガイドは,ビジネス継続性(BC)とディザスタリカバリ(DR)のアーキテクチャ計画と,Citrix虚拟应用程序和桌面のオンプレミスとクラウドの両方の展開に関する考慮事項を支援します。【中文翻译】:。Citrixは、このドキュメントは、全体的なDR戦略の包括的なガイドではないことを認識しています。DRのすべての側面を考慮しているわけではなく、さまざまなDRの概念についてより素人の用語の視点を取る場合があります。
このガイドは,組織のCitrixアーキテクチャに大きな影響を与える次の考慮事項について説明し,それに関連するアーキテクチャに関するガイダンスを提供することを目的としています。
- 我的意思是
- vs。高可用性
- ディザスタリカバリ層の分類
- ディザスタリカバリオプション
- クラウドでのディザスタリカバリ
- 这是一个很好的例子
我的意思是
Citrix設計手法の”ビジネス・レイヤー”に合わせて,明確なビジネス要件とサービスのリカバリに関する既知の制約を収集します。思杰(Citrix):。このステップにより,範囲が明確になり,ビジネス要件と機能要件,制約を満たすのに最適な博士戦略の方向性が提供されます。
。思杰(Citrix) DR、DR、DR、DR、DRディザスタリカバリオプション通情达理,通情达理。
- バックアップ戦略とRTO(目標復旧時間)現在,サーバに使用しているバックアップ戦略は何ですか。バックアップ頻度?保存期間?オフサイトストレージ?テスト済みですか吗?。()。Citrixがホストするアプリケーションが接続するアプリケーションバックエンドをディスカッションに含めると、期待を一致させることができます。
- rpo()。RPO(目標復旧時点)では,博士で許容できるデータ損失の程度はどれくらいですか。。。0分?1時間??Citrixインフラストラクチャでは,この考慮事項は,データベースの変更とユーザーデータ(プロファイル,フォルダーリダイレクトなど)にのみ適用されます。RTOと同様に,Citrixでホストされるアプリケーションのバックエンドについても検討する価値があります。
- 【翻译】この考慮事項には,Citrixインフラストラクチャだけは含まれませんが,Citrixがホストするアプリケーションクライアントがインターフェイスするユーザーデータまたは主要なアプリケーションサーバーを含めることができます。Citrixプラットフォームをリカバリする時間とCitrixでホストされているアプリケーションをリカバリする時間の間に差異があるかどうかを識別することが重要です。この時間デルタは,ソリューションの一部のみがオンラインであるため,システム停止を延長できます。
- 汪汪汪汪。Citrixプラットフォームは,多くの場合,ビジネスの重要度レベルが異なる多数のユースケースに対応しています。?。。Citrix環境の新たな機能である場合は、DRの有効化を区分化するために、ユースケースのセグメント化と優先順位付けを推奨します。
- 機能。。。ホストされた共有デスクトップまたは特定のアプリケーションソロによって提供されるVDIの使用例もあります。英文:には、DRではコンポーネントの冗長性(ADC、コントローラ、StoreFront、SQLなど)は必要ないと認識されている場合がありました。このような決定は、生産の長期停止がある場合のリスクとみなすことができます。
- 博士。他のCitrix環境やその他のインフラストラクチャサービスに対して,既存の博士戦略または計画が存在していますか。新しいルーティング可能なサブネットにリカバリするか,または”バブル”ミラーリング本番ネットワークにリカバリしますか。博士この回答は,現在のアプローチ,ツール,または優先順位を可視化するのに役立ちます。
- 。この考慮事項は,Citrixの最終的なリカバリ戦略を決定することはできませんが,次の点を理解することが重要です。
- 回復:組織内で利用できるストレージレプリケーションテクノロジ,VM回復テクノロジ(VMware SRM, Veeam Zerto, Azureサイト回復(ASR)など)は何ですか吗?Citrix依存関係と一部のCitrixコンポーネントはそれらを使用できます。
- Citrix:?コンポーネントによっては,特定のリカバリ戦略にうまく活用できないものもあります。MCSまたはpvによって管理される非永続的な環境は,ストレージやネットワークとの緊密な統合により,VMレプリケーションテクノロジの候補が不十分になります。
- 。。?中文:。?。
- 就是这样。この決定はかなり重要ですが,企業のBCまたは博士プランを通じて事前に確立することもできます。この要件は,多くの場合,リカバリ場所を決定しています。この戦略は,アプリケーション・レベルでのみサービス・リカバリに対応することを意図していますか。ハードウェアラック間?地下鉄の場所にありますか吗?2 . ?2 . ?クラウドプロバイダーリージョン内またはクラウドプロバイダのインフラストラクチャ全体(マルチリージョン)内ですか
- 。?この決定はイ博士ベント中に手動で変更する必要がある企業のネットワーク接続など,サービスのリストア先に影響する可能性があります。。
- 。各ユーザーセッションの平均消費トラフィック(ICA,アプリケーション,ファイルサービス)はどれくらいですか吗?。
- 。博士の状況が解決された後,本番環境でのサービス復帰方法について,組織には既存の計画がありますか。組織はどのように通常の状態に回復するのですか吗?中文:。
。★★★★★★★★★★★★★★★★★★★★★★★★★★★
- 。この決定により,レプリケーションまたはリカバリに使用できるテクノロジーと使用できないテクノロジー,それらの使用方法,RTO,施設間の最小距離が決定されます。
- 。使用するハードウェアの種類や利用可能なネットワーク帯域幅などに関するディレクティブはありますか?これらの考慮事項は,RPO(目標復旧時点)に関する考慮事項に影響を与えることもあれば,リスクたとえば,内博士のファイアウォールやネットワークパイプのサイズが小さすぎる場合,ネットワークの依存関係では博士ワークロードを処理できないため,最終的にシステム停止につながる可能性があります。または,コンピューティングの場合,ハイパーバイザーホストのサイズが小さいのか,異なるハイパーバイザーの使用がオプションに影響を与える可能性があります。ネットワーキングに関して,WANのサービス時に,リカバリサイトのネットワークスループット機能が実稼働環境よりも制約を受けている場合。クラウド環境,特に数千席に拡張する場合,仮想ファイアウォール,VPNゲートウェイ,クラウドツーWANアップリンク(AWS直接连接,Azure ExpressRoute,谷歌クラウドインターコネクトなど)などのコンポーネントサービスの制限により,この潜在的なリスクが急速にボトルネックになる可能性があります。)。
- 予算。。。
- 地理。指定された博士ファシリティが特定された場合は,に博士接続するユーザーに加えて,本番環境から施博士設へのレイテンシーなどの考慮事項についても理解する必要があります。
- データの常駐またはデータのクラス分けこの決定により,ロケールとテクノロジー,または回復方法の面でオプションが制限されます。
- 。?
- 。バックエンドの依存関係を持つCitrixでホストされるアプリケーションにはBC /博士プランがありますか吗?> > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > > >Citrixは高速リカバリ用に設計できますが、コアアプリケーションにリカバリプランがない場合、またはRTO(目標復旧時間)が拡張されたリカバリプランがない場合、このリスクはDRにおけるCitrixプラットフォームの有用性に影響を与える可能性があります。
- 。。。博士のネットワークフローが本番環境と異なる場合は,博士シナリオでは,SSL的共识,ICAプロキシ,GRE,またはIPSec VPNのICAトラフィックカプセル化の使用が必要になることがあります。
【中文翻译】:
博士Citrix,この記事では設計の最も一般的な誤解の1つに,2つのデータセンターにまたがる単一のコントロールプレーンが博士を構成するという概念があります。我的意思是,我的意思是,我的意思是。データセンターにまたがる単一のCitrixサイトまたはpvファーム(近くにあるものも含む)は,高可用性設計を構成しますが,博士設計ではありません。お客様によっては,このパスを,機博士能に対する管理の簡素化を重視するビジネス上の意思決定として選択しているお客様もいます。店面サーバーグループのスパニングは,接続された(低レイテンシー)データセンター間でのみサポートされています。“”,“”,“”,“”,“”,“”,“”,“”,“”CTX220651」)。
次の図は,前述の根拠のために博士プラットフォームではないマルチデータセンターのHA Citrixアーキテクチャの例です。このリファレンスアーキテクチャは,物理的に分離された2つのデータセンター施設が互いに近接しており,低レイテンシー,広帯域幅の相互接続性により,1つの論理データセンターとして扱うお客様が使用します。このアーキテクチャでは,博士またはHAのニーズを満たすことはほとんどないため,博士計画とCitrixの環境も推奨されます。

上記のHA概念リファレンスに加えて,ゾーンを適用するHAアーキテクチャは,地理的な冗長性を提供したいが,プラットフォームを完全にリカバリする必要がないお客様にも利用できます。従来のIMAアーキテクチャ(XenApp 6.5以下)のゾーン概念は,菲利普-马萨用に再設計され,XenDesktop 7.7で再導入され,7.11での大きな機能強化により,サイト内のさまざまな冗長性機能が提供され,複数ロケーション展開における課題を解決できます。
ゾーンプリファレンス(7.11以降)機能を使用するサイトアーキテクチャでは,同一のCitrixリソースが複数のゾーンに展開され,単一のデリバリーグループに集約されます。ゾーンの優先度 (特定のリソースに対して他のゾーンにフェイルバックする機能) は、アプリケーション、ユーザーのホームゾーン、またはユーザーの場所に基づいて制御できます。このテーマの詳細については、区域偏好内部。XenDesktop 7.6vda自動更新機能により,VDAはサイト内のすべてのコントローラのローカルキャッシュの最新のリストを維持できます。この機能を使用すると,ローカル交付控制器または云连接器がローカルゾーンで使用できなくなった場合に,サテライトゾーン内のVDAをプライマリゾーンにVDAに登録できます。店面:。★★★★ユーザーがプライマリゾーンが使用できない場合でも、ローカルアクセス層からリソースにアクセスし続けることを推奨します。

これらのサポートされるHAオプションとは対照的に,次の図は,地理的に離れたデータセンターまたはクラウドリージョンにまたがる,サポートされていない,または推奨されていないコンポーネントアーキテクチャを示しています。。プラットフォーム安定性の問題は,このような展開におけるレイテンシーの問題によっても発生する可能性があります。。“”“”“”“”“”“”“”“”

# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #中核となるCitrix虚拟应用程序和桌面は主にプレゼンテーションと配信プラットフォームです。Citrixコントロールプレーンは、独自の可用性とリカバリ設計がCitrixプラットフォームのDR要件を満たしている他のコンポーネント(ネットワーク、SQL、Active Directory、DNS、RDS CAL、DHCPなど)に依存します。Citrixが依存しているテクノロジの共有管理ドメインは、Citrix DRソリューションの有効性に影響を与える可能性があります。
ファイルサービス(共有上のユーザーデータやビジネスデータなど)と,Citrixがホストするアプリケーションおよびデスクトップのインターフェイスを使用するアプリケーションバックエンドに関するリカバリに関する考慮事項は,同様の重要性があり,お客様が完全に考慮されない場合もあります。アプリケーションの準備状況に関する以前のポイントを参照して,Citrix博士プラットフォームは,短いタイムスパンでリカバリするように設計できます。ただし,これらのコアユースケースの依存関係に,Citrixに似たRTO(目標復旧時間)のリカバリプランがない場合,またはリカバリプランがまったくない場合,このプランは,想定したとおりに博士でのフェイルオーバーに成功しても,これらの依存関係が使用できないためにユーザーがジョブ機能を実行できなくなる可能性があります。。博士イベントが発生し,Citrixが内博士の”常時オン”のCitrixプラットフォームにフェイルオーバーし,ユーザーは接続中ですが,EMRアプリケーションは手動によるリカバリにより完了までに数時間または数日かかることがあります。この間,臨床スタッフはオフラインプロセス(ペンと紙)の使用を余儀なくされる可能性が高いでしょう。このような結果は,リカバリ時間やユーザー・エクスペリエンスに対するビジネス全体の期待と一致するものではありません。
DR vs. HA。
(DR)vs. (DR)(哈)
HA与は博士組織のニーズに対応し,リカバリ目標を満たすために不可欠です。哈,医生,哈哈,医生,哈哈,哈哈,哈哈,哈哈。中文:哈,哈,医生。
- 哈,。サービスは,ユーザーの中断を最小限に抑えて,別のシステムにフェイルオーバーできます。このソリューションは,クラスタ化または負荷分散されたアプリケーションと同じくらいシンプルで,本番構成を反映し,常に利用可能な,より複雑なアクティブまたはスタンバイの”ホット”または”常時オン”のインフラストラクチャに実行できます。これらの構成では,フェイルオーバーは自動化される傾向があり,”地理冗長”配置と呼ばれることもできます。
- 主は博士に代替データセンター(またはクラウドプラットフォーム)へのサービスのリカバリ(アプリケーションレベルの重大な障害またはデータセンターの致命的な物理的障害による)に関係しています。。“”“”“”“”“”“”“”“”“”サービスの冗長性やフォールトトレランスは関係せず,一般的に,複数のタイプの障害に耐えるより広範な戦略です。
高可用性は,設計仕様とソリューションの展開に組み込まれる傾向がありますが,は博士サービスのリカバリを実行するためのスタッフとインフラストラクチャリソースのオーケストレーション計画に大きく関係しています。
?我不知道。。たとえば,上記のHAの説明の2番目の例は,ソリューションに関連する他の非Citrixコンポーネントの適切なリカバリと組み合わせて,サービス(Citrix)が反対側のデータセンターにフェイルオーバーする高可用性博士ソリューションとみなします。この特定のアーキテクチャは,アクティブ——パッシブまたはアクティブ——アクティブとして,すべてのユーザーに対してアクティブ——パッシブ,別のデータセンターよりも優先するユーザーのアクティブ——アクティブ,または2つのデータセンター間で負荷分散を行うアクティブ——アクティブ(アクティブ——アクティブ)など,さまざまなマルチサイト反復で実装できます。このようなソリューションの設計時には,スタンバイ容量を考慮し,考慮し,負荷を継続的に監視し,必要に応じて博士に対応できる容量を確保する必要があります。
また,ソリューションの整合性を維持するために,博士コンポーネントを本番環境でも最新の状態に保つことも不可欠です。このアクティビティは,最適な意図でこのようなソリューションを設計および導入し,本番環境においてより多くのプラットフォーム・リソースを消費し始め,ソリューションの博士整合性を維持するために利用可能な容量を増やすことを忘れるお客様には見落とされることがよくあります。
Citrixのコンテキストでは,2つのデータセンター間でCitrix管理ドメイン(Citrixサイト,pvファームなど)にまたがる場合,公表されたガイダンスのとおりに地理的にローカライズされた2つのファシリティなどのように,博士を構成せず,店面サーバーグループなどの一部のコンポーネントでは構成されません。【翻译】公表されたガイダンスのとおりのpvのデータベースレイテンシーの制限により,このような展開もサポートされない可能性があります。。★★★★公表されたガイダンス。
多くのCitrixコンポーネントはデータベースなどの依存関係を共有しているため,2つのデータセンター間に管理境界を延長しても,いくつかの主要な障害シナリオから保護されません。データベースが破損した場合,障害ドメインは両方のファシリティのアプリケーションサービスに影響を与えます。HA Citrixソリューションをに博士十分であると見なすには,第2のファシリティでは主要な依存関係や管理境界を共有しないことをお勧めします。たとえば,ソリューション内のデータセンターごとに個別のサイト,ファーム,およびサーバーグループを作成します。リカバリ・プラットフォームを可能な限り独立させることにより,コンポーネント・レベルの障害による本番環境と災害復旧環境の両方への影響を軽減します。この考慮事項はCitrixにとどまらず,本番環境と博士環境間で異なるサービスアカウント,ファイルサービス,DNS,国家结核控制规划,ハイパーバイザ管理,認証サービス(广告,半径など)を使用することも推奨され,単一障害点を軽減することもできます。
ディザスタリカバリ層の分類
博士の階層分類は,アプリケーションまたはサービスの重要度を明確にするため,組織の博士戦略の重要な側面です。これはRTO(およびそのレベルのリカバリを達成するためのコスト)を決定するためです。。ビジネスの重要度およびRTO(目標復旧時点)に基づいて,さまざまな相互依存を異なる分類に分解できるため,コスト重視の災害復旧ケースを最適化できます。
以下は,Citrix上でホストされているCitrixインフラストラクチャサービス,その依存関係,および重要なアプリケーションまたはユースケース(およびVDAに関連付けられている)を評価する際の参考となる層博士分類の例です。Dr .,。組織では,各自のリカバリ目標とクラス分けのニーズに合わせて,博士階層のクラス分けを適用または開発することが推奨されます。
災害復旧階層 0
【中文翻译】:
目標復旧時間:0
目標復旧時点:0
0- 10 - 10
コア它インフラストラクチャ
- ネットワークとセキュリティインフラストラクチャ
- ネットワークリンク
- (,)
コア它サービス
- 活动目录
- DNS
- DHCP
- ファイルサービス
- RDS
- (Citrix)
0-
。これらのコンポーネントは,分離されたネットワークセグメントではなく,他の階層の依存関係であるので,博士ロケーションで常に使用できます。。Citrixが重要なアプリケーションをホストしている場合は、Tier 0プラットフォームと見なされます。このようなシナリオでは、CitrixインフラストラクチャはDRに「ホット」展開されます。
【中文译文
【中文译文】
目標復旧時間:4 時間
Rpo(): 15分
階層 1-分類例
重要なアプリケーション
- ウェブサイトとウェブアプリ
- crm
- 基幹業務アプリケーション
思杰
- 管理
- カスタマーサービスまたはセールス
- 它
1-
ビジネスが中核的なビジネスアクティビティを実行するアプリケーションまたは仮想デスクトップは,通常,この階層に含まれます。また,階層0と同様の”ホット・スタンバイ”博士アーキテクチャを採用するか,自動レプリケーション/フェイルオーバー・ソリューションのメリットを享受できます。クラウドにプロビジョニングする場合は,RTOターゲットに影響を与える可能性があるため,考慮事項这就是我的梦想。
2 .中文
【中文译文】
目標復旧時間:48時間
Rpo(): 1个
2 .中文
重要でないアプリケーション重要でないCitrixでは,階層1または階層0アプリケーションの機能に影響を与えないユーザーデータを使用します。
2-
。ただし,短期的に利用できない場合には,財務,評判,運用上の重大な影響を引き起こす可能性は低いアプリケーションまたはユースケース。これらのアプリケーションは,バックアップからリカバリされるか,自動リカバリ・ツールによって最も低い優先度でリカバリされます。
3 .中文
【中文翻译】:
目標復旧時間:5 日間
目標復旧時点:8 時間
第3层
使用頻度の低いアプリケーション
3-
停止の影響がごくわずかであるアプリケーションは,最大1週間まで利用できません。。
4 .中文
【中文译文】
目標復旧時間:30 日
rpo(英文):24
4 .中文
非実稼働環境
4-
アプリケーション,インフラストラクチャ,VDIの停止によってビジネス・オペレーションへの影響もごくわずかになり,長期間にわたってリストアできます。また,RPO(目標復旧時点)を拡張することも,性質によってはまったく使用しない場合もあります。これらのRPO(目標復旧時点)は,バックアップからリカバリすることも,で博士新規に構築することもでき,リカバリすべき最後の階層とみなされます。
Citrix博士プランニングで階層分類が重要なのはなぜですか吗?
齐格、齐格、齐格、齐格、齐格。
- Citrix ?重要なのは,Citrixが重要であるとみなされ,ホストするアプリケーションが重要であると見なされた場合,Citrixインフラストラクチャはクリティカルに分類されます。
- Citrix。中文:医生?
最初の質問では,多くのエンタープライズCitrix展開は,重要なアプリまたはデスクトップの配信により,階層0に分類される傾向があります。これは,ネットワーク,Active Directory, DNS,ハイパーバイザーインフラストラクチャなど”常にオン”の階層です。齐格思(Citrix),齐格思(Citrix),齐格思(Citrix)すべてのCitrixユースケースを階層1以上に該当する場合は,层0として扱うと,博士プロセスの全体的なコストと複雑さに影響を与える可能性があります。
2 .中文:Citrix,★★★★★★★★★★★★)(中文:)クラウドでは”,常時稼働する”アプリケーションまたはデスクトッププラットフォームに対応することと,ビジネス上の重要度が低いと考えられるアプリケーションやデスクトップに対して,コスト面で大きな考慮事項があります。このような考慮事項は,本番環境におけるアプリケーションやユースケースの分離(サイロ)にも影響し,博士プラットフォームでの導入の柔軟性を活用できます。
Citrixの博士設計を確立する場合,Citrix自体の範囲を超えて議論を行うことは,ビジネスユニットに期待値を設定するのに役立ちます。たとえば,Citrix環境は”常時稼用“サービスとみなされ,代替データセンターで可用性が高くなります。ただし,Citrixのホストされるアプリケーションが依存している重要なアプリケーションバックエンドは,リカバリが起動された後も数時間使用できなくなります。このギャップにより,2つのプラットフォーム間でリカバリ時間の差異が生み出され,リカバリ中に誤解を招くユーザーエクスペリエンスを提供できます。。当初期待値を設定すると,すべての関係者に対して,リカバリエクスペリエンスがどのように見えるかを適切に把握できます。状況によっては,Citrixを反対側の施設でホットスタンバイ(常にオン)に保ち,アクセス層のフェイルオーバーを手動で制御して,プラットフォームの可用性に関する誤解を避けることができます。
ディザスタリカバリオプション
このセクションでは,一般的なCitrixリカバリ戦略について,その長所と短所,主な考慮事項について説明します。思杰(Citrix),。。また,このセクションでは,初期の段階で示された主要な質問への回答が博士設計にどのように影響するかについても説明します。
以前の博士の質問の相関関係が多すぎると,次の質問トピックでは,Citrix博士の設計上の意味が次のように表示されます。
- バックアップ戦略とRTO(目標復旧時間)CitrixインフラストラクチャまたはCitrixから提供されるアプリケーションがミッションクリティカルと判断された場合,複数のデータセンターにホットスタンバイまたはアクティブ——アクティブのCitrixインフラストラクチャが存在する”常時オン”モデルを採用する必要があります。このアーキテクチャでは,各データセンター(個別のCitrixサイト,該当する場合はpvファーム,店面サーバーグループなど)に複数の独立したCitrixコントロールプレーンが作成されます。Citrixインフラストラクチャのコントロールプレーンにまたがっても,博士(データセンターにまたがるサイトやサテライトゾーンを使用するなど)博士はを構成しません。。
- 【翻译】Citrixが博士のホットスタンバイ(常時オン)容量で展開され,コアビジネスアプリケーションのバックエンドがリカバリに8時間かかる場合,自動アクセス層フェイルオーバーを採用するのは意味がありません。。
- 汪汪汪汪。災害復旧シナリオで業務運用を維持するために,重要なワークロードまたはコアアプリケーションのみをCitrixで迅速にリカバリする必要がある場合は,このシナリオによって容量の観点からは災害復旧コストを削減できます。,你怎么看リカバリ階層化戦略ごとのビジネスへの影響と対照的なユースケースごとの重要性の分類では,容量コストを削減することはできませんが,它スタッフにリカバリ優先順位の順序をより集中的に提供することができます。
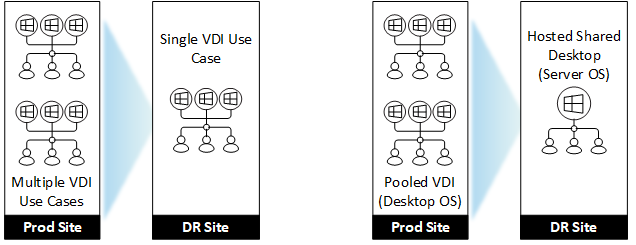
- 機能。HDX洞察力、会话记录などの特定のコンポーネントが,博士プラットフォームの運用に重要ではないと判断された場合,博士環境におけるそれらの省略により,複雑さとメンテナンスのオーバーヘッドが軽減されます。同様に,災害復旧シナリオの多くのユースケースが,よりシンプルで汎用的なCitrix提供オプションを博士で維持できる場合,これにより複雑さとコストが軽減されます。たとえば,技術的に実現可能な場合は,プールされたVDIの代わりにホストされた共有デスクトップを使用するか,ビジネス運用に有害でない限り,複数のユースケースを1つに集約します。
- 博士。たとえば,組織の既存の博士戦略が,データレプリケーションおよびオーケストレーションツールを使用してCitrixおよびその他のアプリケーションインフラストラクチャをリカバリする場合,ほとんどのCitrixコンポーネントがこのモデルに適しています。プラットフォームのサイズと単一イメージ管理テクノロジへの依存が本番プラットフォーム要件である場合,多くの場合,このようなテクノロジは適切ではありません。ホットスタンバイのCitrixプラットフォームのハイブリッドアプローチと,おそらくマスターイメージのレプリケーションがより適切である可能性があります。
- 。博士でのリカバリにプロファイルが重要であると見なされる場合は,適切なレプリケーション・テクノロジーが必要となる場合があります。多くの組織ではシ博士ナリオのプロファイルにはあまり関心が無く,新規作成を受け入れています。この考慮事項は,Citrixでアクセスされるユーザーデータ(フォルダリダイレクト,マップされたドライブ)にも適用されます。このデータのRPO(目標復旧時点)とRTO(目標復旧時間)は,ビジネス上の判断となります。さらに,多くの永続的なVDIが,博士にそのまま保持できるほど重要であると見なされる場合(ユーザーがソフトウェアの再インストールなどを要求する場合など),これらの仮想マシンをレプリケーション用に考慮する必要があります。。
- 就是这样。。英文:がデータセンターまたはクラウドリージョン内のCitrixインフラストラクチャの高可用性のみを必要とする場合、このタイプの災害では、管理コンポーネントが冗長であり、反対側のインフラストラクチャで動作していることを確認するだけで済みます。たとえば、StoreFront サーバーペアの種類では、VMware 非アフィニティルールを使用して、クラスタ内の異なるホスト上で動作するか、データセンター内の異なるクラスタ上で動作するか、あるいは異なる可用性セットの一部として動作します。このような状況では、冗長コントロールプレーンを完全に作成する必要はほとんどありません(複数のCitrixサイトやStoreFront サーバーグループなど)。ただし、DR がリージョンに関係なく複数のデータセンターを対象とする場合は、各データセンター (AD、DNS、SQL、ハイパーバイザーなど) でローカル依存関係を使用する冗長コントロールプレーンの方が適しています。お客様がグローバルであり、複数のデータセンターを使用して、これらのデータセンターにローカルなアプリケーションバックエンドでCitrixサービスを提供する(または計画している)場合、地理的にローカライズされたアクティブ-アクティブ HA-DR アーキテクチャの方が適切である可能性が高くなります。このアーキテクチャでは、地理的にローカライズされたCitrixインフラストラクチャを使用して、必要に応じてセカンダリの優先順でバックアップデータセンターにフェイルオーバーできるため、可能な限り最適なユーザーエクスペリエンスをユーザーに提供します。
- 。上記のユーザー,アプリ,およびデータのローカリゼーションに関する考慮事項以外に,一部のクライアントユーザネットワークは,インターネットやWANへの発信通信を制限できるセキュリティデバイス(プロキシ,ファイアウォールなど)を使用して比較的ロックダウンできます。この状態がクライアントネットワークに適用されるかどうかを考慮し,Citrixサービスの新しいIP(店面VIPおよびVDA IP,またはCitrix网关IPなど)をローカルセキュリティ構成で考慮して,ローカル局域网セキュリティによるリカバリの遅延が発生しないようにすることが重要です。博士を起動するときの制限準備の観点からは,博士が発生した場合,クライアント・アクセスは何らかの方法で変化しますか。顧客の災害復旧シナリオによっては,WANが使用できず,すべてのユーザーがインターネット経由でCitrixリソースにアクセスする必要があると仮定できます。このような手順では,公元前および準備計画に文書を作成し,サポートデスクへの負担をさらに軽減するために,エンドユーザー(サポートされているCitrixクライアントの詳細,企業またはBYODデバイスへのアクセスに関する前提条件)に関する前提条件(企業またはBYODデバイスへのアクセスに関する前提条件)を設定する必要があります。
- 。VDAトラフィック(ICAアプリケーション,ファイルサービス)に関するネットワーク帯域幅の使用量は,施博士設のネットワークサイジングとファイアウォールを考慮する必要があります。この考慮事項は,VPNゲートウェイと仮想ファイアウォールの容量に制限があるクラウド環境で特に重要です。VDAからの本番トラフィックを監視して,サイジングの平均値を決定することは,ネットワークを効果的にサイズ設定するために重要です。ネットワークの制約がある場合,組織は呼び出された場合に,予測される博士トラフィックの負荷に対応するために,異なるネットワーク構成を使用する必要があります。思杰SD-WAN, WAN,。
- 。博士で変更されたユーザー・データ,または災害復旧中にVDAイメージがある場合,組織はこれらの変更を本番環境に反映するためにフェイルバックを計画する必要があります。。ユーザーデータの場合は,レプリケーションの順序を逆にしてリカバリするのと同じくらい簡単です。【翻译】Citrixインフラストラクチャでは単一のイメージ管理テクノロジーを使用しない場合です。MCSまたはPVSを使用している場合は、マスターイメージまたはvDiskを本番環境に手動でレプリケートし、それに応じてVDAを更新できます。

Citrixの一般的な回復オプションの概要を次に示します。それぞれの適応はフィールドに存在しますが,比較のためにそれぞれの基本的なバージョンを概説しています。オプションは,最も単純な(多くの場合,RTO,低コスト)から,より高度なもの(RTOは低いがコストが高い)まで構成されています。特定の組織にとって理想的な選択肢は,利用可能な它スキル,予算,インフラストラクチャに加えて,ホストされたアプリケーションやユースケースのリカバリ時間を調整することです。さらに,多くのオプションは,実現可能ですが,ADCや単一イメージ管理テクノロジーなどのネットワークおよびストレージと統合されたCitrixテクノロジーは,“常にオン”のリカバリモデル以外の方法には適していないことを示しています。技術的に達成することは不可能というわけではありませんが,それらの達成に伴う複雑さのレベルによって,リカバリのリスクが高くなり,人為的なミスが生じやすくなります。
リカバリオプション——オフラインバックアップからのリカバリ

英文怎么说
長所:
- レプリケーションまたはホットスタンバイソリューションに比べてメンテナンスコストの削減
短所:
- ダウンタイムへの大きな影響
- より大規模で詳細なリカバリプラン博士(オーケストレーション)ドキュメント
- 你怎么看
- バックアップの整合性と経過時間に依存する
- 【中文翻译】:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译
- McS
- ネットワークのためCitrix VPX ADCには適していません(
nsconfigディレクトリとns.confファイルのバックアップを適用して再構築する必要がある)
ユースケースと前提条件
成熟度の低い它組織や它運用予算が限られている組織にとって有用であり,コアビジネスサービスを回復するために長期にわたるシステム停止が発生する可能性があります。バックアップの復元の整合性を定期的にテストし,明確に文書化されたリカバリ・プロセスに従うことを前提としています。
リカバリオプション:レプリケーションによるリカバリ

英文怎么说
長所:
- レプリケーションは自動化されている可能性が高く,RTO(目標復旧時点)とRPO(目標復旧時点
- 自動リカバリ・ソリューションに比べて,あまり複雑でないテクノロジーを使用している可能性が高い
短所:
- 你知道吗
- より大規模で詳細なリカバリプラン博士(オーケストレーション)ドキュメント
- 【中文翻译】:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译:中文翻译
- McS。。ただしに博士ダミーマシンカタログを作成するか,または博士でVDAインスタンスをスケールアウトし,複製されたマスターイメージを適用する”カタログの更新“アクションを実行すると,このRTO(目標復旧率)を短縮できます。
- ネットワーキングのためCitrix VPX ADCには適していないため,ホットスタンバイADCの採用に適している
ユースケースと前提条件
。このソリューションは,圣ベンダーまたはハイパーバイザーベンダー(vSphere复制など)のストレージレプリケーションテクノロジを使用して,WAN経由で別の施設にVMをレプリケートします。
リカバリオプション:自動リカバリによるレプリケーション

英文怎么说
長所:
- ホットスタンバイソリューションに比べてメンテナンスコストの削減
- レプリケーションは自動化されている可能性が高く,RTO(目標復旧時点)とRPO(目標復旧時点
- リカバリ・プランは自動化される傾向がある
- 管理介入と人的ミスを少なくする
短所:
- VMware SRM, Veeam Zerto, ASRなどの先進的なテクノロジーに依拠し,リカバリを調整し,ネットワーク・パラメータを変更する
- McS。。ただしに博士ダミーマシンカタログを作成するか,または博士でVDAインスタンスをスケールアウトし,複製されたマスターイメージを適用する”カタログの更新“アクションを実行すると,このRTO(目標復旧率)を短縮できます。
- ネットワーキングのためCitrix VPX ADCには適していないため,ホットスタンバイADCの採用に適している
ユースケースと前提条件
。このソリューションは,前のオプションと同じストレージレプリケーションに依存しますが,特定の順序での仮想マシンのリカバリ,NIC構成の調整(必要な場合)などを行う博士オーケストレーション・テクノロジーが含まれています。
()

英文怎么说
長所:
- プラットフォームが”常時オン”であるため,リカバリ時間が短い
- vpx, mcs, pv,
- リカバリ計画(DRオーケストレーション)に関するドキュメントの削減
短所:
- URLをフェイルオーバーしたり,ユーザーをバックアップURLに誘導したりするには,管理者による介入が必要的
- “
- スタンバイプラットフォームの構成と更新を本番環境と同期させるため,管理オーバーヘッドが増大する
ユースケースと前提条件
。ホットスタンバイの”完全にスケーリング”プラットフォームまたは”オンデマンドスケーリング”プラットフォームを使用できます。。制限事項。
フェイルオーバー時に,管理者は,**1* *, Citrix网关および店面の1つ以上の博士IPを指しています。または,ユーザーは”バックアップ”または“博士”URLを使用して開始するように正式な通信によって通知されます。
この手動オプションは,アプリケーションのバックエンドに長いリカバリ時間が必要になりますが,Citrixが完全に利用可能で,アプリケーションが利用可能でない場合,ユーザーの混乱を招くシナリオに役立ちます。
このモデルは,成熟した它組織と,フェイルオーバーをサポートするために十分なWANと計算インフラストラクチャを使用できることを前提としています。
リカバリオプション:自動フェイルオーバー機能を備えたホットスタンバイ(アクティブ/パッシブ)

英文怎么说
長所:
- プラットフォームが”常時オン”であるため,リカバリ時間が短い
- vpx, mcs, pv,
- 最小限のリカバリプラン博士(オーケストレーション)ドキュメント
- URLのフェイルオーバーとしてエンドユーザーが簡単に
- 思杰网关(Citrix Gateway)
短所:
- に博士”ホット”ハードウェアがスタンバイ状態にあり,Citrix ADCライセンスに搭載されているため,コストが高くなります
- 【中文翻译
- スタンバイプラットフォームの構成と更新を本番環境と同期させるため,管理オーバーヘッドが増大する
ユースケースと前提条件
企業のお客様と共通の構成で,Citrix ADC GSLB (ADC以先进上が必要)を介して博士サイトへの自動フェイルオーバーを可能にします。このモデルは,成熟した它組織と十分なWANを想定し,フェイルオーバーをサポートするためのインフラストラクチャを計算します。また,このモデルでは,アプリケーションとユーザーデータの依存関係が,最新のアクティブサイトのバージョン/更新と整合しており,同様に自動化された方法施博士で設でリカバリ可能であることを前提としています。これにより,エンドユーザに対するサービスの長期間の影響や部分的なソリューション機能による混乱を軽減できます。
リカバリ・オプション:自動フェイルオーバー機能を備えたアクティブ/アクティブ

英文怎么说
長所:
- プラットフォームが”常時オン”であるため,リカバリ時間が短い
- vpx, mcs, pv,
- 最小限のリカバリプラン博士(オーケストレーション)ドキュメント
- エンドユーザーにシームレスに
短所:
- に博士”ホット”ハードウェアがスタンバイ状態にあり,Citrix ADCライセンスに搭載されているため,コストが高くなります
- 【中文翻译
- スタンバイプラットフォームの構成と更新を本番環境と同期させるため,管理オーバーヘッドが増大する
- アクティブ/アクティブGSLBは現在,Citrix网关でのEPAスキャンをサポートしていません。思杰网关(Citrix Gateway
- 管理者は,すべてのデータセンターでリソースとハードウェアの容量を監視および調整し,プラットフォームが拡張しても博士容量の整合性が影響を受けないことを確認
ユースケースと前提条件
企業のお客様にはより高度で一般的な構成で,アクセス層のURLをCitrix ADC GSLB経由でアクティブ——アクティブ動作させることができます(ADC以先进上が必要)。この機能は,ローカルデータセンターが互いに近接している環境,またはデータセンターをリモートにできるが,ユーザーをお好みのデータセンターにピン留めする手段を備えている場合(多くの場合,高度な店面構成とGSLBによって制御される程度は少ない)マルチサイトのシナリオで役立ちます。
このモデルは,成熟した它組織と十分なWANを想定し,フェイルオーバーをサポートするためのインフラストラクチャを計算します。また,このモデルでは,アプリケーションとユーザー・データの依存関係が最新のサイトのバージョン/更新と一致し,同様に自動化された方法施博士で設でリカバリ可能であることを前提としています。これにより,エンドユーザに対するサービスの長期的な影響や部分的なソリューション機能による混乱を軽減できます。
パブリッククラウドでのディザスタリカバリ
オンプレミスからクラウドプラットフォームへのディザスタリカバリまたはクラウドからクラウドへの障害復旧には,オンプレミスのリカバリシナリオでは存在しない独自の課題や考慮事項があります。
博士設計計画では計博士画時にクラウドインフラストラクチャを適用する博士プランが無効,コストがかかる,または目標容量を満たすことができない状態になる原因を回避するために,次の主な考慮事項に対処できます。
-
インパクトエリア
可用性パフォーマンスコスト
詳細
お客様は,仮想ファイアウォール,VPNゲートウェイ,およびWANアップリンク(AWS直接连接,Azure表达路线,GCPクラウドインターコネクトなど)を含むクラウドソリューション内のスループットジャンクションポイントを過小評価し,それゆえに小さくなる可能性があります。Citrixプラットフォームをクラウドに復旧し,わん現在,Azure VPN网关とAWS交通网关の上限は1.25 Gbpsです。この制限は,クラウドアーキテクチャにとって重要な場合,ゲートウェイをスケールアウトしたり,複数のVPC (AWSがある場合)を使用したりする必要があります。多くの仮想ファイアウォールでは,処理できるスループットにライセンス制限があり,最大限でも最大限に達しています。この制約では,ファイアウォールの数をスケールアウトし,何らかの方法でそれらを負荷分散する必要があります。
推奨事項
。。
- ica
- セキュリティ境界を通過する場合の,セッションあたりのアプリケーション通信帯域幅の見積もり
- セキュリティ境界を通過する場合の,セッションあたりのファイルサービスの推定帯域幅
上記のメトリックでは,本番環境のVDAとの間で送受信される現在のトラフィックパターンに関するデータを収集すると便利です。また,これらのネットワークパスを使用することが予想されるCitrixとは無関係な他のデータフローも考慮する必要があります。Citrix博士の計画には,ネットワークチームとセキュリティチームと協力して,セキュリティゾーンおよびネットワークセグメントを通過する帯域幅の見積もりが理解され,対応できることを確認します。帯域幅が重視される場合,Citrix SD-WAN WAN最適化は,回線上でのセッションフットプリントの削減や,複数のネットワーク接続にわたる帯域幅の集約に役立ちます。
Windows操作系统
インパクトエリア
コスト
詳細
異なるクラウドプラットフォームで実行されている微软桌面操作系统インスタンスについては,ライセンスに関する考慮事項が複雑になる可能性があります。2019年8月微软中文:。
推奨事項
ユースケースアーキテクチャを決定する際には,微软の最新のガイダンスを参照してください。博士ソリューションでVDIに潜在的なコストの問題がある場合は,可能であれば,ホスト共有デスクトップ(RDS卡尔の拡張が必要な場合があります)を補足することを検討してください。これは,より低い運用コストで高い柔軟性を実現できるからです。
考慮事項:VDAスケールアウトのタイミング博士(の前または実行中)
インパクトエリア
【翻译
詳細
。このソリューションでは,使用されているかどうかにかかわらず,予約済みインフラストラクチャに支払われないため,博士コストを大幅に削減できます。
しかし,大規模な場合,クラウドプロバイダーは一度に数百または数千の仮想マシンをパワーオンするSLAにコミットすることはできません。このソリューションは,博士用のVDAフットプリントが数百または数千のインスタンスに実行することが予想される場合,特に困難になります。クラウドプロバイダーは,手元にさまざまなインスタンスサイズの大容量を維持する傾向がありますが,このプロバイダーは瞬間によって異なる場合があります。地理的領域に影響を与える災害が発生した場合,オンデマンド容量を要求する他のテナントからの競合が発生する可能性があります。
★★★★★★★★★★★★★★★★
- 【中文翻译
- 。
- 博士の時点でスケールアウトすることは可能ですか?その場合は,各ユースケースのさまざまなRTO(目標復旧時間)をよりよく理解するために,段階的な容量不足をサポートするために,博士階層によってユースケースに優先順位を付けていますか。
- アプリまたはホストされた共有デスクトップユースケースをサポートするOSインスタンスをスケールアップして,プロビジョニング時間を節約し,運用コストを節約するためにこれらのインスタンスをパワーオフすることはできますか吗?
推奨事項
RTO期間内に予想される容量をパワーオンできるかどうか,およびオンデマンドインスタンスで満たすことができるかどうかを判断するために,まずクラウドプロバイダと連携することをお勧めします。博士シナリオでVDAの容量可用性の制限を回避するには,できるだけ多くのアベイラビリティーゾーンでVDAをプロビジョニングすることをお勧めします。大規模では,さまざまなクラウドリージョンにまたがってプロビジョニングを行い,それに応じてアーキテクチャを調整する価値があります。一部のクラウドプロバイダーは,VMの消費をさらに軽減するために,さまざまなサイズのVMインスタンスタイプを採用することを提案しています。可能であれば,VDAインスタンスを事前にプロビジョニングし,オフラインのままにしておき,定期的に更新することが賢明です。プロビジョニングはリソースと時間のかかるプロセスであり,事前プロビジョニングを行うことで,オンデマンドでVDAの博士容量をスケールアウトできます。組織がキャパシティ可用性のリスクをほとんど求めていない場合は,リソースの可用性を保証するために,予約済みまたは専用のコンピューティングキャパシティを適用し,それに応じて予算を作成することが必要になる場合があります。。特定のユースケースでは,VDAをすぐに利用できるようにする必要がありますが,その使用例では,VDAの維持に重要度が低い場合は,数日または数週間という長いRTO(目標復旧時間)でリカバリできる柔軟性もあります。是啊。
考慮事項——アプリケーションデータとユーザーデータ
インパクトエリア
コスト可用性パフォーマンス
詳細
ユーザーデータとアプリケーションバックエンドの場所は,Citrix博士環境のパフォーマンス,場合によっては可用性に顕著な影響を与える可能性があります。。この場合,すべてのアプリケーションバックエンドやユーザーデータ(ホームドライブや部門ドライブなど)をCitrixと一緒にクラウドにリカバリすることはできません。このギャップにより,予期せぬ待ち時間が発生し,アプリケーションのパフォーマンスや機能に影響を与える可能性があります。スループットの観点から,このギャップは,利用可能なネットワークおよびセキュリティアプライアンスの帯域幅にさらに負担をかける可能性があります。
推奨事項
可能な場合は,アプリケーションデータとユーザーデータを内博士のCitrixプラットフォームに対してローカルに維持し,WAN全体のレイテンシーと帯域幅の要求を軽減することにより,パフォーマンスを可能な限り最適な状態に維持します。
思杰云(Citrix Cloud
博士計画に関してCitrix云が提供するCitrix虚拟应用程序和桌面(CVAD)のオンプレミスまたは”従来の”展開と,Citrix云が提供するCitrix虚拟应用程序和桌面サービス(CVADS)には,いくつかの顕著な違いがあります。
- Citrixは,パートナー/顧客のほとんどの制御コンポーネントを管理し,Citrixサイトとそのコンポーネントに関する重要な博士要件をその責任から排除します。
- Citrixリソース用の博士環境を展開するには,お客様がリカバリの”リソースの場所“にCitrix云连接器を展開し,必要に応じてCitrix网关用の店面およびCitrix ADCを展開する必要があります。
- Citrix云独自のサービスアーキテクチャは,地理的に冗長性が高く,耐障害性に優れています。
- Citrix工作区およびCitrix网关サービスを使用している場合は,アクセス層の博士は必要ありません。
これらの主な相違点を超えて,以前のセクションの博士に関する考慮事項の多くは,引き続きパートナー/顧客の計画が必要です。★★★★CitrixGateway ServiceとCitrix WorkspaceサービスがCitrix Cloudから使用されない場合、Citrix VDA、ユーザーデータ、アプリケーションバックエンド、およびCitrix Access層に対する責任が維持されるからです。
このセクションでは,Citrix云の適切な博士戦略を定義する際に役立つ重要なトピックについて説明します。
CVADSは災害復旧をシンプル化
以下に,CVADSの概念アーキテクチャの概要を説明した典型的な概念図を示します。さらに,Citrix管理コンポーネントおよびパートナー/顧客管理コンポーネントの責任の分離も示しています。ここでは説明していない电话,分析,およびCitrix网关の”サービス”は,CVADSに関連する選択的なCitrix云コンポーネントであり,“Citrixによる管理”に該当します。

この図に示すように,リカバリに関する決定を必要とする制御コンポーネントのかなりの部分は,Citrixの管理範囲に該当します。CVADSアーキテクチャは,クラウドベースのサービスであるため,思杰云【中文】:★★★★CitrixCloudの「秘密のソース」の一部であり、Citrix Cloud SLA英文:中文:
。
- Citrixコントロールプレーンを使用し,使用中の場合は”サービス”にアクセスします(ワークスペース,Citrix网关サービス)。
- 英文:リソースの場所コンポーネント(云连接器、VDAアプリケーションバックエンド,インフラストラクチャの依存関係(广告、DNSなど),およびアクセス層(店面、Citrix ADC)などのCitrix云アクセス層を使用していない場合。
お客様は,CVADSでのディザスタリカバリに関して,次のメリットを得られます。
- 管理対象のコンポーネントの数が少なく,サイト間で複製および保守する独立した構成が少なくなるため,管理上の負担が軽減されます。
- クラウド内の”Citrixサイト”の一元化された構成により,Citrix展開環境間で人為的なミスや構成の不一致が発生する可能性が軽減されました。
- 構成および保守するCitrixサイトとコンポーネントの数が少なく,場所間で管理するアクセス層がない(オプション),およびCitrixリソース用のディザスタリカバリロジックが複雑でないため,本番環境と障害復旧環境のリソース管理の簡素化により,運用が合理化されます。
- 導入と保守に必要なサーバ・コンポーネントの数を減らし,運用コストを削減し,監視データベースの一元化により,導入環境全体の傾向を一元的に把握できます。
Cvads (Cvads)
リカバリ計画のための多くのコンポーネントはお客様の管理範囲から削除されますが,お客様は,リソース・ロケーション内にあるコンポーネントの博士および高可用性(オプション)のプランニングと管理,および高可用性(オプション)の責任を負います。
。Cvads,ゾーン> > > > > >ゾーンプリファレンス。従来導入されたCVADサイト内で区偏好を使用すると,高可用性設計と見なされますが,有効な博士設計とは見なされません。思杰云,。
() () (ディザスタリカバリオプション。
Citrix云のCVADSサービスの博士を計画する際には,インフラストラクチャ計画の観点からのいくつかの主要な指針を理解する必要があります。
- 。DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR DR
- 云连接器。云连接器、云连接器、云连接器、云连接器、云连接器。明確にするために,云连接器は,博士イベント中に手動または自動で”リカバリ”する必要があるコンポーネントではありません。これらは”ホットスタンバイ”コンポーネントとみなされ,各ロケーション内でオンライン状態に保たれる必要があります。
- 访问控制器()。お客様は,Citrix网关および店面サーバー用に独自のCitrix ADCを展開し,Citrix工作区またはCitrix网关サービスを使用しないことを選択できます。★★★★★★★★★★★★★★★★
- カスタム認証フロー
- 【翻译
- HDXトラフィックルーティングの柔軟性が向上
- 1 .齐姆
- 云连接器のCitrix云への接続が切断された場合でも,店面で云连接器のローカルホストキャッシュ機能を使用して操作を続行する機能
云连接器と同様に,店面およびCitrix网关コンポーネントをリカバリ場所に”ホットスタンバイ”として展開し,博士イベント中はリカバリしないことをお勧めします。
这是一个很好的例子
博士プラットフォームを維持することは,プラットフォームが必要なときに予期せぬ問題を回避するために,その整合性を維持するために不可欠です。DR Citrix。
- 思杰博士。”“ホットスタンバイ環境をお持ちのお客様は,コーナーをカットし,博士をテストプラットフォームとして扱うことができます。★★★★★★★★★★★★★実際は博士非本番環境では展示されていない方法でメンテナンスが壊滅的に間違っている場合でも,そのユーティリティに影響を与えないように,変更を促進する最後のプラットフォームになる可能性があります。
- パッチ適用とメンテナンス”“ホットスタンバイCitrixプラットフォームを使用する場合,運用環境とのロックステップでの定期的なメンテナンスは,博士プラットフォームの機能を維持するために不可欠です。操作系统,Citrix製品,アプリケーションパッチに関して,博士を実稼働環境と同期させることが重要です。リスクを軽減するために,本番環境のパッチ適用から博士へのパッチ適用までの間に数日から1週間かかることが推奨されます。
- 这是我的梦想。博士に本番環境のリカバリ施設へのレプリケーションや”ホット・スタンバイ”環境の使用に関わらず,リカバリ・プロセスを熟知し,プラットフォームやワークフローに欠陥があることを確認するために,災害復旧計画を定期的にテスト(年2回以上が理想的)することが重要です。★★★★★★★★★★
- 【翻译】アクティブ——パッシブとアクティブ——アクティブの”常にオン”のCitrix環境の両方で,本番環境における容量またはユースケースの変更も博士についても考慮する必要があります。特にactive - activeモデルを使用すると,リソース使用率が,各環境でリソースの定常状態使用率しきい値が50%増加するのは簡単です。これはイ博士ベントが発生し,存続しているプラットフォームが過負荷になり,パフォーマンスの低下または障害が発生した場合に限られます。過負荷。。
概要
Citrixのディザスタリカバリに関する話題については,かなりの根拠を取り上げました。Citrixリカバリ戦略を計画する際に考慮すべきアーキテクトとお客様向けの、このガイドの主なメッセージと要点を以下に示します。
- お客様の環境のビジネス要件と技術力を理解することは,Citrixに必要なディザスタリカバリ戦略に影響を与えます。■■■■■■■■■■■■■■■■■■■■■
- 。。
- 。
- 組織のテクノロジー・ポートフォリオの災害復旧階層の分類を開発することで,リカバリ戦略を開発する際の可視性,柔軟性,コスト削減を実現できます。
- CitrixインフラストラクチャまたはCitrix上でホストされているアプリケーションのRTO(目標復旧時間)要件は,ディザスタリカバリ設計が必要となる最も重要な影響要因です。。
- ”“ホットディザスタリカバリプラットフォームを採用していないCitrixの災害復旧アーキテクチャでは,Citrix MCS, ADC,プロビジョニングなど,お客様が使用できるテクノロジに制限があります。
- Citrixのディザスタリカバリ戦略では,ユーザーデータとアプリケーションバックエンドのリカバリ時間とリカバリ時間も考慮する必要があります。Citrixは迅速にリカバリできるように設計できますが、アプリケーションとデータの依存関係が同様の時間内に利用できないと、ユーザーは作業できなくなります。
- 。組織では,クラウド環境でディザスタリカバリを呼び出すときに,予期しないボトルネックや運用上の影響を回避するために検討する必要があります。
- プラットフォームの整合性を維持するために,災害復旧コンポーネントを本番環境の更新と構成に合わせて最新の状態に保つことが不可欠です。
- サイト間でCitrixのアクティブ/アクティブ構成を使用するプラットフォームでは,障害が発生した場合に,1つ以上の正常な場所で予測される負荷をサポートするのに十分なリソースを確保するために,容量の監視に十分対応する必要があります。
- お客様は,Citrixの障害復旧計画を定期的にテストして,その運用とコア目的に応える能力を検証する必要があります。
- Citrix虚拟应用程序和桌面服务は博士アーキテクチャの多くの側面を大幅に簡素化し,ゾーン設定構成によるリソースの場所の冗長化を可能にします。
ソース
(1)、(2)、(3)、(4)、(3)、(4)、(3)、(4)、(3)、(4)この作業を容易にするために,独自のニーズに適応できるソース図を提供します:ソースダイアグラム。