
Design Decision: Disaster Recovery Planning
Overview
本指南协助业务连续性(BC)nd disaster recovery (DR) architecture planning and considerations for both on-prem and cloud deployments of Citrix Virtual Apps and Desktops. DR is a significant topic in breadth of scope in and of itself. Citrix acknowledges this document is not a comprehensive guide to overall DR strategy. It does not consider all aspects of DR and at times takes a more layman’s terms perspective on various DR concepts.
This guide is intended to address the following considerations which have significant impact on an organization’s Citrix architecture and provide architectural guidance related to them:
- Business Requirements
- Disaster Recovery vs. High Availability
- Disaster Recovery Tier Classifications
- Disaster Recovery Options
- Disaster Recovery in the Cloud
- Operation Considerations
Business Requirements
Aligning to the “Business Layer” of Citrix design methodology, gathering clear business requirements and known constraints for recovery of service. Documenting these items is the starting point in the development of any recovery plan for Citrix. This step helps gain clarity on scope and provide direction on the DR strategy most suitable to meet the business and functional requirements, and constraints.
Following are few examples of useful questions to discuss. These questions are discussed in more detail in theDisaster Recovery Optionssection in terms of how they affect a Citrix DR design:
- Backup Strategy and Recovery Time Objective (RTO).What backup strategy is used today for servers? Backup frequency? Retention period? Offsite storage? Tested? Does the Citrix platform must be immediately available in the event of a disaster or brought online within a specific time period? (See Disaster Recovery Tier Classifications). It is worth including application back-ends which Citrix-hosted apps connect to into the discussion to align expectations.
- Recovery Point Objective (RPO).RPO什么程度的数据损失被认为是托尔erable for DR, which can vary depending on the infrastructure component or data classification? How old can the recovered data for the service be? 0 minutes? An hour? A month? Within the context of the Citrix infrastructure, this consideration can apply only to database changes and user data (profiles, folder redirection, and so on). As with RTO, it is worth considering the application back-ends for Citrix-hosted apps into the discussion.
- Scope of Recovery.This consideration does not include just the Citrix infrastructure, but can include user data or key application servers which Citrix-hosted application clients interface with. It is important to identify if there is going to be a disparity between time to recover the Citrix platform, and time to recover applications hosted on Citrix. The time delta can prolong an outage as only part of the solution is online.
- Use Cases.Citrix platforms often service numerous use cases, each with different levels of business criticality. Does recovery cover all Citrix use cases? Or key use cases upon which the business’s operational success is fully dependent on. The answer has a large impact on infrastructure scoping and capacity projections. Segmentation and prioritization of use cases is recommended to compartmentalize the enablement of DR if it is a net new capability for the Citrix environment.
- Capabilities.Are there any key capabilities which don’t need to be included in DR which can reduce cost? An example of this capability would be the use of persistent desktops vs. non-persistent; some VDI use cases which can be served by Hosted Shared Desktops, or even specific application solos. Customers have at times indicated component redundancy (ADCs, Controllers, StoreFront, SQL, and so on) are not considered necessary in DR. Such decisions can be viewed as a risk if there is a prolonged outage of production.
- Existing DR.Does an existing DR strategy or plan exist for other Citrix environments and other infrastructure services? Does it recover into new routable subnets or into a “bubble” mirroring production networks? The answer can help give visibility to current DR approaches, tools, or precedence.
- Technology Capabilities.This consideration cannot dictate the final recovery strategy for Citrix, however it is important to understand:
- Recovery:What storage replication technologies, VM recovery technologies (VMware SRM, Veeam, Zerto, Azure Site Recovery (ASR), and so on) are available within the organization? Some Citrix components alongside Citrix dependencies can use them.
- Citrix:What Citrix technologies are in use for image management and access? Some components cannot lend themselves well to certain recovery strategies. Non-persistent environments managed by MCS or PVS make for poor candidates for VM replication technologies due to their tight integration with storage and networking.
- Data Criticality.Are user profiles or user data deemed critical to recovery? Persistent VDIs? If this data is unavailable when DR is invoked, would this cause significant impacts to productivity? Or can a non-persistent profile or VDI be used as a temporary solution? This decision can drive up costs and solutions complexity.
- Types of Disasters.This decision is fairly significant but also can be pre-established through a corporate BC or DR plan. This requirement often dictates recovery location. Is the strategy intended to accommodate for recovery of service at the application level only? Between hardware racks? Within a metro location? Between two geographies? Two countries? Within a cloud provider region or an entire cloud provider’s infrastructure (multi-region)?
- Client Users.Where are the users located who access the services in production? This decision can have implications as to where service is restored to, including corporate network connectivity which can require manual modifications during a DR event. In addition, the answer dictates access tier considerations.
- Network Bandwidth.How much traffic (ICA, application, file services) does each user session consume on average? This decision applies both to cloud and on-prem recovery.
- Fallback (or Failback).Does the organization have pre-existing plans for how to return to service in production once the DR situation has been resolved? How does the organization recover to a normal state? How is new data that can have been created in DR reconciled and consolidated with production?
Constraints limit BC/DR design options or their configurations. They come in many forms but can include:
- Regulatory or Corporate Policy.This decision can dictate what technologies can or cannot be used for replication or recovery, how they are used, RTO, or minimum distance between facilities.
- Infrastructure.有类型的硬件指令是我们吗ed, network bandwidth available, and so on? These considerations can impact RPO considerations or can even present risks. For example, undersized firewalls or network pipes in DR can ultimately lead to outages as network dependencies cannot handle the DR workload. Or, in the case of compute, undersized hypervisor hosts or use of different hypervisors entirely can impact options. With regards to networking, if the recovery site happens to have more constrained network throughput capability versus production when servicing the WAN. In cloud environments, especially when scaling into thousands of seats, this potential risk can quickly become a significant bottleneck due to component service limitations such as virtual firewalls, VPN gateways, and cloud-to-WAN uplinks (AWS Direct Connect, Azure ExpressRoute, Google Cloud Interconnect, and so on).
- Budget.DR solutions come with costs that can conflict with project budgets. More often than not, the shorter the RTO, the higher the cost.
- Geography.If a designated DR facility has been identified, considerations such as latency from production to DR facilities, in addition to users connecting to DR must be understood.
- Data Residency or Data Classification.This decision can limit options in terms of locales and technologies or recovery methods.
- Cloud Recovery.Is there a mandate for infrastructure to be recovered in cloud vs. in an on-prem facility?
- Application Readiness.Do the applications hosted on Citrix that have back-end dependencies have a BC/DR plan and how do the RTOs line up to Citrix’s target RTO? Citrix can be designed for rapid recovery but if core applications do not have a recovery plan or one with an extended RTO, this risk likely impacts the usefulness of the Citrix platform in DR.
- Network Security.Does the organization have security policies that might dictate what traffic segments require encryption in transit? Does this consideration vary depending on the network link being traversed? The answer might require in DR scenarios the use of SSL VDA, ICA Proxy, GRE, or IPsec VPN encapsulation of ICA traffic if network flows for DR are different from production.
Misconceptions on Disaster Recovery (DR) Design
一个最常见的误解Citrix DR designs is the notion that a single control plane spanning two data centers constitutes DR. It does not. A single Citrix Site or PVS Farm spanning data centers, even ones near, constitutes a high availability design, but not a DR design. Some customers choose this path as a business decision valuing simplified management over DR capability. StoreFront Server Groups spanning issupportedonly between well-connected (low latency) data centers. Similarly, has documented latency maximums to consider when deploying across data centers as outlined inCTX220651.
The following diagram is an example of a multi-data center HA Citrix architecture that is not however, a DR platform due to the previously mentioned rationale. This reference architecture is used by customers who treat two physically separate data center facilities as a single logical data center due to their close proximity to each other and low latency, high bandwidth interconnectivity. A DR plan and an environment for Citrix would still be recommended as this architecture would be unlikely to satisfy the needs of either DR or HA.

In addition to the HA conceptual reference above, HA architectures based on zones are available for customers who want to provide cross-geo redundancy but do not require the platform to be fully recoverable. The zones concept from legacy IMA architecture (XenApp 6.5 and below) was re-engineered for FMA and reintroduced in XenDesktop 7.7 with major enhancements in 7.11 allows for various intra-site redundancy capabilities which can solve challenges for multi-location deployments.
网站架构中使用zone preference(7.11及以后)特性,相同的Citrix资源es are deployed across several zones and aggregated into a single Delivery Group. Zone preference (with the ability to fail back to other zones for a given resource) can be controlled based on application, user’s home zone, or user location. Refer toZone Preference Internalsfor more information on this subject. TheVDA Registrationauto-update feature (introduced in XenDesktop 7.6) allows VDAs to maintain a locally cached up-to-date list of all controllers within a Site. This function allows VDAs within the satellite zone to fail over registration to VDAs to the primary zone in the event their local Delivery Controllers or Cloud Connectors become unavailable in their local zone. StoreFront Server Groups are present in each zone location, as is recommended for users to continue accessing resources from their local access tier in the event of the primary zone being unavailable.

这些支持公顷选项相比,指出lowing diagram illustrates unsupported or ill-advised component architectures spanning geographically distant data centers or cloud regions. These diagrams provide neither effective HA nor DR due to the distance and latency between components. Platform stability issues can also result due to latency concerns in such a deployment. Furthermore, the stretching of administrative boundaries between sites does not align to DR principals. We have seen similar conceptual designs by customers in the past.

Another common misconception is the depth of consideration that a Citrix DR solution can include. Citrix Virtual Apps and Desktops at its core is primarily a presentation and delivery platform. The Citrix control plane depends on other components (networking, SQL, Active Directory, DNS, RDS CALs, DHCP, and so on) whose own availability and recovery design meet the DR requirements of the Citrix platform. Any shared administrative domain of technologies on which Citrix is dependent can impact the efficacy of the Citrix DR solution.
Of similar importance and occasionally not fully accounted for by customers are recovery considerations for file services (user data and business data on shares, and so on) and application back-ends with which Citrix-hosted applications and desktops interface. Referencing the earlier point on application readiness, a Citrix DR platform can be designed to recover in short timespans. However, if these core use case dependencies do not possess a recovery plan with RTO similar to Citrix or no recovery plan at all, this plan can affect Citrix successfully failing over in DR as expected but users being unable to perform their job functions as these dependencies remain unavailable. Take for instance a hospital who hosts their core EMR application on Citrix. A DR event occurs and Citrix fails over to an “always on” Citrix platform in DR and users are connecting, but the EMR application is recovered via more manual means which can take hours or days to complete. Clinical staff would likely be forced to use offline processes (pen and paper) during this time. Such an outcome cannot be congruent to the overall expectation of the business for recovery time or user experience.
The next section will discuss DR vs. HA in more detail.
Disaster Recovery (DR) vs. High Availability (HA)
Understanding HA vs. DR is critical in aligning to organizational needs and meeting recovery objectives. HA is not synonymous with DR, but DR can use HA. This guide interprets HA and DR as follows:
- HA is regarded as providing fault tolerance for a service. A service can fail over to another system with minimal disruption to a user. The solution can be as simple as a clustered or load balanced application to a more complex active or standby “hot” or “always on” infrastructure that mirrors the production configurations and is always available. Failover tends to be automated in these configurations and can also be termed a “geo-redundant” deployment.
- DR is concerned primarily with the recovery of service (due to significant app-level failure or catastrophic physical failure of the data center) to an alternate data center (or cloud platform). DR tends to involve automated or manual recovery processes. Steps and procedures are documented to orchestrate recovery. It is not concerned with redundancy or fault tolerance of the service and is generally a broader scope strategy that withstands multiple types of failures.
While HA tends to be embedded into design specifications and solutions deployment, DR is largely concerned with the orchestration planning of personnel and infrastructure resources to invoke recovery of the service.
Can HA include DR? Yes. For enterprise mission-critical IT services, this concept is common. Take for instance the second example in the HA description above, coupled with appropriate recovery of other non-Citrix components related to the solution, would be regarded as a highly available DR solution wherein a service (Citrix) fails over to an opposing data center. That particular architecture can be implemented as Active-Passive or Active-Active in various multi-site iterations such as Active-Passive for all users, Active-Active with users preferring one data center over another, or Active-Active with users being load balanced between two data centers without preference. It is important to note that when designing such solutions, standby capacity must be considered, accounted for, and load monitored on an ongoing basis to ensure capacity remains available to accommodate DR, if it is required.
It is also essential that DR components be kept up-to-date with production to maintain the integrity of the solution. This activity is often overlooked by customers who design and deploy such a solution with the best of intentions, then start consuming more platform resources in production, and forget to increase available capacity to retain the DR integrity of the solution.
In the context of Citrix, spanning Citrix administrative domains (Citrix Site, PVS Farm, and so on) between two data centers such as two geo-localized facilities as perpublished guidancewould not constitute DR and for some components such as StoreFront Server Groups. Similarly, due to PVS’s database latency limitations perpublished guidance, such a deployment would also be likely unsupported. Supportability constraints between geos also extend to Citrix Site and Zone design sometimes, due to latency maximums between satellite controllers and the databases perpublished guidance.
As many Citrix components share dependencies such as databases, stretching administrative boundaries between the two data centers would not protect against several key failure scenarios. If databases became corrupt the failure domain would impact application services at both facilities. To regard an HA Citrix solution as being sufficient for DR, we recommend the second facility does not share key dependencies or administrative boundaries. For instance, create separate Sites, Farms, and Server Groups for each data center in the solution. By enabling a recovery platform to be as independent as possible we reduce the impacts of component-level failures from affecting both production and DR environments. This consideration also extends beyond Citrix, and using different service accounts, file services, DNS, NTP, hypervisor management, authentication services (AD, RADIUS, and so on) between production and DR environments is also recommended to reduce single points of failure.
Disaster Recovery Tier Classifications
Tier classifications for DR are an important aspect of an organizations DR strategy as it provides clarity into application or service criticality which in turn dictates the RTO (and thus costs for accomplishing that level of recovery). Generally, the shorter the RTO, the higher the DR solution cost. Being able to break down various inter-dependencies into different classifications (based on business criticality and RTO) can help optimize cost-sensitive DR cases.
Below is a set of sample DR tier classifications to serve as a reference when assessing the Citrix infrastructure services, its dependencies, and critical applications or use cases (and associated to VDAs) hosted on Citrix. DR tiers are outlined in order or recovery priority with 0 being the most critical. Organizations are encouraged to apply or develop a DR tiering classification aligning with their own recovery objectives and classification needs.
Disaster Recovery Tier 0
Tier 0 - Recovery Objectives (Examples)
Recovery Time Objective: 0
Recovery Point Objective: 0
Tier 0 - Classification Examples
Core IT Infrastructure
- Network and security infrastructure
- Network links
- Hypervisors and dependencies (compute, storage)
Core IT Services
- Active Directory
- DNS
- DHCP
- File Services
- RDS Licensing
- Critical End User Services (Citrix)
Tier 0 - Notes
这对核心infrastruc分类主要是ture components. These components are always available in the DR location as they are dependencies for other tiers, and not in an isolated network segment. They need to be provisioned and maintained alongside their production equivalents. If Citrix is hosting critical applications, it’s likely regarded as a Tier 0 platform. In such scenarios, the Citrix infrastructure is deployed “hot” in DR.
Disaster Recovery Tier 1
Tier 1 - Recovery Objectives (Examples)
Recovery Time Objective: 4 Hours
Recovery Point Objective: 15 Minutes
Tier 1 - Classification Examples
Critical Applications
- Websites and web apps
- ERPs and CRM applications
- Line-of-business applications
Citrix Use Cases
- 管理
- Customer Service or Sales
- IT Engineering & Support
Tier 1 - Notes
Applications or virtual desktops upon which the business depends on to carry on core business activities would typically be contained in this tier. They would likely also employ a similar “hot standby” DR architecture as Tier 0 or benefit from an automated replication and failover solution. If provisioning into cloud, considerationsdiscussed later, need to be accounted for as they can impact RTO targets.
Disaster Recovery Tier 2
Tier 2 - Recovery Objectives (Examples)
Recovery Time Objective: 48 Hours
Recovery Point Objective: 1 Hour
Tier 2 - Classification Examples
Non-critical Applications Non-critical Citrix use cases User Data that does not impact the functionality of Tier 1 or Tier 0 apps.
Tier 2 - Notes
Applications or use cases which are key to business operations, but whose short-term unavailability is unlikely to cause serious financial, reputation, or operational impacts. These applications are either recovered from backups or recovered as lowest priority by automated recovery tools.
Disaster Recovery Tier 3
Tier 3 - Recovery Objectives (Examples)
Recovery Time Objective: 5 Days
Recovery Point Objective: 8 Hours
Tier 3 - Classification Examples
Infrequently Used Applications
Tier 3 - Notes
Applications with negligible outage impact are unavailable up to one week. These applications are likely recovered from backups.
Disaster Recovery Tier 4
Tier 4 - Recovery Objectives (Examples)
Recovery Time Objective: 30 Days
Recovery Point Objective: 24 Hours or None
Tier 4 - Classification Examples
Non-production environments
Tier 4 - Notes
Applications, infrastructure, and VDIs whose outages also have a negligible impact on business operations and can be restored over an extended time. They can have an extended RPO as well, or not at all depending on their nature. These RPOs can be recovered from backups or built brand new in DR and is regarded as the last tier to be recovered.
Why is Tier classification important for Citrix DR planning?
Tier classification is important for Citrix for the following reasons:
- How critical is the Citrix infrastructure to business operations? It is important to consider that if Citrix is deemed important but an application it hosts is regarded as critical, the Citrix infrastructure would become classified as critical.
- The use cases or core business applications which Citrix hosts; do they have different DR tier classifications?
For the first question, many enterprise Citrix deployments tend to be classified as Tier 0 due to delivery of critical apps or desktops; the “always on” tier like network, Active Directory, DNS, and hypervisor infrastructure. This circumstance may not always be the case however for every Citrix use case. Treating every Citrix use case as Tier 0 when some can fall into Tier 1 or higher can impact the overall cost and complexity of the DR process.
The second question stresses classification by Citrix use case and lends its importance most significantly in cloud environments which isdiscussed later in more detail. In cloud, there are significant cost considerations between accommodating for “always on” application or desktop platforms, vs. applications or desktops regarded as being less business critical. Such considerations can also influence application or use case isolation (silos) in production to take advantage of deployment flexibility in a DR platform.
When establishing a DR design for Citrix, bringing the discussion beyond the scope of Citrix itself is useful to set expectations to business units. As an example, a Citrix environment is deemed to be an “always on” service and is made highly available in an alternate data center, yet the critical application back-ends which Citrix’s hosted applications depend upon will remain unavailable for several hours as the recovery is invoked. This gap creates a recovery time disparity between the two platforms and can provide a misleading user experience during the recovery. Citrix is available immediately but key applications are not functional. Setting expectations at the outset provides appropriate visibility to all stakeholders on what the recovery experience can look like. In some situations, a customer can want to keep Citrix on hot standby (always on) in the opposing facility but manually control the failover of the access tier, to avoid misunderstandings on platform availability.
Disaster Recovery Options
In this section, common Citrix recovery strategies are outlined including their pros and cons, and key considerations. Other recovery capabilities or variations of the following themes for Citrix are possible, this section is focusing on some of the most common. In addition, this section illustrates how responses to the core questions indicated early on influence the DR design.
Correlating too several of the earlier DR questions, the following question topics have Citrix DR design implications as follows:
- Backup Strategy and Recovery Time Objective (RTO).If Citrix infrastructure or applications served from Citrix are deemed mission critical, it is likely Citrix must employ an “always on” model where hot standby or Active-Active Citrix infrastructure is present at two or more data centers. This architecture would result in multiple independent Citrix control planes being created at each data center (separate Citrix Sites, PVS farms if applicable, StoreFront Server Groups, and so on). Spanning the control planes for the Citrix infrastructure does not constitute DR (ex. spanning a Site across data centers or using satellite zones); doing so if the business is anticipating a DR platform for Citrix, that counters to that mandate.
- Scope of Recovery.If Citrix is deployed in a hot standby (always on) capacity in DR but the core business application back-ends take, for example, 8 hours to recovery, it cannot make sense to employ an automated access tier failover. Manual failover of the access tier can be more appropriate.
- Use Cases.If only critical workloads or core applications must be rapidly recovered in Citrix to maintain business operations in a DR scenario, this scenario can likely reduce DR costs from a capacity perspective. If multiple use cases of differing priorities need recovery, the classification of importance per use case contrasted to business impact per the recovery tiering strategydiscussed earliercannot reduce capacity costs but will provide IT staff a more focused set of recovery priority orders.
- Capabilities.If certain components such as HDX Insight, Session Recording are not deemed critical to DR platform operation, their omission in the DR environment removes some complexity and maintenance overhead. Similarly, if many use cases in a DR scenario can subsist on a simpler and more generic Citrix delivery option in DR, this can also reduce complexity and costs. For example, using a Hosted Shared Desktop instead of Pooled VDI if technically feasible, or aggregating more use cases into one, provided they are not detrimental to business operations.
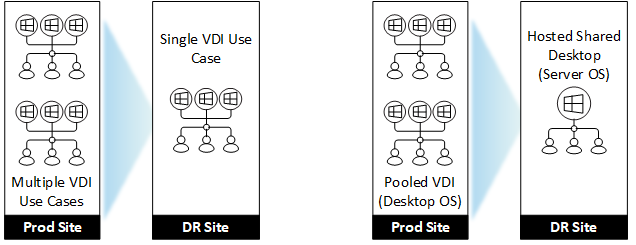
- Existing DR.If the existing DR strategy of the organization, for example, recovers Citrix and other application infrastructure using data replication and orchestration tools, most Citrix components can be suitable for this model. If the size of the platform and reliance on single-image management technology is a production platform requirement, then often such technologies cannot be suitable; a hybrid approach of a hot standby Citrix platform and perhaps replication of master images can be more appropriate.
- Data Criticality.If profiles are deemed critical for recovery in DR, appropriate replication technology can be necessary. Many organizations are less concerned with profiles in DR scenarios and accept them being created new. This consideration will also apply to user data accessed in Citrix (folder redirection, mapped drives); RPO and RTO for this data can be a business decision. Furthermore, if many persistent VDIs are deemed important enough to retain intact in DR (versus requiring users to reinstall their software, and so on) then these VMs must be considered for replication, which can incur extra costs to support recovery.
- Types of Disasters.客户想保护的程度ainst failure can dictate various architectural changes. If the customer only wants HA of the Citrix infrastructure within the data center or cloud region, this type of disaster can merely require ensuring management components are both redundant and operating on opposing infrastructures. As an example, a type of StoreFront server pair uses VMware anti-affinity rules to operate on different hosts in a cluster, or on different clusters entirely within the data center, or perhaps as part of different availability sets. This situation seldom requires creating redundant control planes entirely (multiple Citrix Sites and StoreFront Server Groups for example). However, if DR is intended to encompass multiple data centers regardless of region, then redundant control planes using local dependencies at each data center (AD, DNS, SQL, hypervisor, and so on) is more appropriate. If the customer is global and employs multiple data centers to service Citrix (or plans to) with respective application back-ends local to these data centers, then it is more likely that a geo-localized Active-Active HA-DR architecture is more appropriate. This architecture provides users with the most optimal user experience when possible, by using geo-localized Citrix infrastructures which can if need be, fail over to a backup data center in a secondary preference order.
- Client Users.Beyond relation to the above point about user, app, and data localization considerations, some client user networks can be relatively locked down with security devices (proxy, firewall, and so on) which can restrict outbound communication to the Internet or even the WAN. It is important to consider if this state applies to the client networks and ensure that new IPs for Citrix services (such as StoreFront VIP and VDA IPs, or Citrix Gateway IP) are accounted for in their local security configurations to ensure further recovery delays do not occur due to local LAN security restrictions when invoking DR. From a preparedness perspective, in the event of DR, will client access change in some fashion? In some DR scenarios for a customer can assume the WAN is unavailable and all users must access Citrix resources via the Internet. Such steps would need documentation in the BC and readiness plans, with pre-requisites established for end-users (regarding supported Citrix client details, assumptions on corporate or BYOD device access) to remove barriers for users returning to service, further reducing the burden on the support desk.
- Network Bandwidth.The amount of network bandwidth used with regards to VDA traffic (ICA, applications, file services) must be factored into DR facility network sizing and firewalls. This consideration is especially important in cloud environments where limits on VPN gateways and virtual firewall capacity exist. Monitoring production traffic from VDAs to determine an average value for sizing is important to effectively size networking. Where network constraints exist, organizations must use different network configurations to accommodate the anticipated DR traffic load if and when invoked. Citrix SD-WAN’s WAN Optimization technology can help with reducing traffic demands.
- Fallback (or Failback).If user data which has changed in DR, or if VDA images while in DR, the organization must plan for failback to propagate these changes back to production, is the production environment prove recoverable. For user data, it can be as simple as reversing the replication order and recovering; similarly, for Citrix infrastructure if not using single image management technologies. If using MCS or PVS, master images or vDisks can be manually replicated back to production and VDAs updated accordingly.

The following list outlines various common recovery options for Citrix. Adaptations of each exist in the field, however for the sake of comparison we are outlining basic versions of each. The options are organized starting with the simplest (often higher RTO and lower cost) through the more advanced (often lower RTO but higher cost). The ideal option for a given organization is to align to recovery time for hosted applications or use cases, in addition to the IT skills, budget, and infrastructure available. In addition, although possible to accomplish, many options indicate that Citrix technologies integrated with network and storage such as ADC and single-image management technologies are not suited for methods other than “always on” recovery models. It is not that it is technically impossible to accomplish, but the level of complexity involved in accomplishing them can make recovery riskier and more prone to human error.
Recovery Option - Recover from Offline Backup

Pros and Cons
Pros:
- Lower maintenance cost compared to replication or hot-standby solutions
Cons:
- High downtime impact
- Larger, more detailed recovery plan (DR orchestration) documentation
- Extended recovery time
- Relies on integrity and age of backups
- Higher degree of human error if manual reconfiguration is necessary (networking, and so on)
- Unsuitable for MCS or PVS
- Unsuitable for Citrix VPX ADC due to networking (and may need to be rebuilt using backups of
nsconfigdirectory andns.conffiles)
Use Case and Assumptions
Useful for less mature IT organizations and organizations with limited IT operations budgets and can allow for extended outages to recover core business services. Assumes backups are tested for restore integrity regularly and follows clearly documented recovery processes.
Recovery Option - Recover via Replication

Pros and Cons
Pros:
- Replication is likely automated and aligns to RTO and RPOs
- Likely uses less complex technologies as compared to automated recovery solutions
Cons:
- Relies on administrative intervention
- Larger, more detailed recovery plan (DR orchestration) documentation
- Higher degree of human error if manual reconfiguration is necessary (networking, and so on)
- Unsuitable for MCS or PVS. Recreation of Machine Catalogs is factored into the projected RTO. However, by creating dummy Machine Catalogs in DR or scaling out VDA instances in DR and performing an “Update Catalog” action applying a replicated master image, this RTO can be shortened
- Unsuitable for Citrix VPX ADC due to networking and thus better suited to employ hot standby ADC
Use Case and Assumptions
Useful for less mature IT organizations and organizations with limited IT operations budgets. This solution relies on storage replication technologies from SAN vendor or hypervisor vendor (vSphere Replication, and so on) to replicate VMs to another facility over the WAN.
Recovery Option - Replication with Automated Recovery

Pros and Cons
Pros:
- Lower maintenance cost compared to hot-standby solutions
- Replication is likely automated and aligns to RTO and RPOs
- Recovery plans tend to be automated
- Less administrative intervention and human error
Cons:
- Relies on more advanced technologies such as VMware SRM, Veeam, Zerto, ASR to orchestrate recovery and modify network parameters
- Unsuitable for MCS or PVS. Recreation of Machine Catalogs must be factored into the projected RTO. However, by creating dummy Machine Catalogs in DR or scaling out VDA instances in DR and performing an “Update Catalog” action applying a replicated master image, this RTO can be shortened
- Unsuitable for Citrix VPX ADC due to networking and thus better suited to employ hot standby ADC
Use Case and Assumptions
Useful for enterprise organizations with appropriate resources and budget for DR facility. This solution relies on the same storage replication of the previous option but includes DR orchestration technologies to recover VMs in particular order, adjust NIC configurations (if needed) and so on
Recovery Option – Hot Standby (Active-Passive) with Manual Failover

Pros and Cons
Pros:
- Short recovery time as platform is “always on”
- Supports storage and network dependent components such as VPX, MCS, PVS
- Lower recovery plan (DR orchestration) documentation
Cons:
- Relies on administrative intervention to fail over URL or direct users to backup URL
- Higher cost due to having “hot” hardware in DR sitting on standby
- Higher administrative overhead to keep standby platform’s configurations and updates in sync with production
Use Case and Assumptions
Useful for enterprise organizations with appropriate resources and budget for DR facility. Can use a hot-standby “fully scaled” platform or a “scale on-demand” platform. The latter can be appealing for cloud recovery to reduce operating costs, withcaveats.
At the time of failover administrators update the**DNS** entry for one or more access URLs to point to one or more DR IPs for Citrix Gateway and StoreFront, or users are advised by formal communication to commence using a “backup” or “DR” URL.
This manual option can be useful for scenarios where application back-ends can require longer recovery time but would add confusion for users if Citrix was fully available and applications were not.
This model assumes a mature IT organization and enough WAN and computes infrastructure are available to support failover.
Recovery Option – Hot Standby (Active-Passive) with Automated Failover

Pros and Cons
Pros:
- Short recovery time as platform is “always on”
- Supports storage and network dependent components such as VPX, MCS, PVS
- Minimal recovery plan (DR orchestration) documentation
- Easier for end-users as URLs fail-over
- Supports EPA Scans at Citrix Gateway
Cons:
- Higher cost due to having “hot” hardware in DR sitting on standby and Citrix ADC licensing
- Higher access tier complexity
- Higher administrative overhead to keep standby platform’s configurations and updates in sync with production
Use Case and Assumptions
A common configuration with enterprise customers and allows for automated failover to the DR site via Citrix ADC GSLB (ADC Advanced or higher needed). This model assumes a mature IT organization and enough WAN and computes infrastructure to support failover. This model also assumes that application and user data dependencies are in alignment with the latest Active site versions/updates and recoverable at the DR facility in a similarly automated manner to reduce prolonged impact of service to the end-user and confusion due to partial solution functionality.
Recovery Option – Active-Active with Automated Failover

Pros and Cons
Pros:
- Short recovery time as platform is “always on”
- Supports storage and network dependent components such as VPX, MCS, PVS
- Minimal recovery plan (DR orchestration) documentation
- Seamless to end-users
Cons:
- Higher cost due to having “hot” hardware in DR sitting on standby and Citrix ADC licensing
- Highest access tier complexity
- Higher administrative overhead to keep standby platform’s configurations and updates in sync with production
- Active/Active GSLB does not currently support EPA scans at Citrix Gateway, Active/Passive GSLB configuration for Citrix Gateway URL suggested
- Relies on administrators to monitor and adjust resource and hardware capacity at all data centers to ensure as platform grows, DR capacity integrity is not impacted
Use Case and Assumptions
A more advanced but common configuration with enterprise customers and allows access tier URLs to operate in an Active-Active manner via Citrix ADC GSLB (ADC Advanced or higher needed). This functionality is useful in environments with local data center proximity to each other, or in situations where data centers can be remote but with the means to pin users to preferred data centers (often driven by advanced StoreFront configurations and GSLB to a lesser extent) for multi-site scenarios.
This model assumes a mature IT organization and enough WAN and computes infrastructure to support failover. This model also assumes that application and user data dependencies are in alignment with the latest site versions/updates and recoverable at the DR facility in a similarly automated manner to reduce prolonged impact of service to the end-user and confusion due to partial solution functionality.
Disaster Recovery in Public Cloud
Disaster Recovery involving on-prem to cloud platforms or cloud-to-cloud comes with its own set of challenges or considerations which often do not present themselves in on-prem recovery scenarios.
The following key considerations can be addressed during DR design planning to avoid missteps which can render the DR plan applying cloud infrastructure either invalid, cost prohibitive, or unable to meet target capacity in the event of DR.
Consideration – Network Throughput
Impact Areas
Availability Performance Cost
Details
Customers can underestimate and thus undersize the throughput juncture points in their cloud solution including virtual firewall, VPN gateway, and WAN uplink (AWS Direct Connect, Azure Express Route, GCP Cloud Interconnect, and so on) if the Citrix platform is to recover in the Cloud and be accessible over the WAN. Azure VPN Gateways and AWS Transit Gateways presently have maximum limits of 1.25 Gbps. This limit can require scaling out gateways or perhaps using multiple VPCs (if there is an AWS) if these are critical to the cloud architecture. Many virtual firewalls have licensed limits on the throughput they can process or maximums even at their highest limit. This constraint can require scaling out the number of firewalls and load balancing them in some manner.
Recommendations
When establishing throughput sizing calculations, assume the full DR capacity load. Capture the following data per concurrent user:
- Estimated ICA session bandwidth
- Estimated application communication bandwidth per session if they traverse security boundaries
- Estimated bandwidth for file services per session if they traverse security boundaries
For the above metrics, it can be useful to gather data on current traffic patterns to and from VDAs in production. It is also important to consider what other data flows unrelated to Citrix are also anticipated to be using these network paths. Be sure to engage the network and security teams in planning Citrix DR to ensure any bandwidth estimates traversing security zones and network segments is understood and can be accommodated for. When bandwidth is at a premium, Citrix SD-WAN WAN Optimization can help with lowering session footprint on the wire or aggregating bandwidth across multiple network connections.
Consideration – Windows Desktop OS Licensing
Impact Areas
Cost
Details
There are potentially complex licensing considerations for Microsoft Desktop OS instances running on different cloud platforms. Microsoftrevised their cloud licensing rightsin August 2019 which can affect VDI cost implications in some deployment scenarios.
Recommendations
Refer to the most current Microsoft guidance when determining the use case architecture. If there is a potential cost challenge for VDI in the DR solution, consider supplementing with Hosted Shared Desktops (augmentation of RDS CALs can be required), if feasible, as they can provide greater flexibility at a lower cost of operation.
Consideration – Timing of VDA Scale Out (Before or During DR)
Impact Areas
Cost Availability
Details
Customers are drawn to cloud by the appeal of paying for capacity only when it is needed. This solution can reduce DR costs dramatically by not paying for reserved infrastructure whether it is used or not.
However at large scales, a cloud provider cannot commit to an SLA of powering on hundreds or thousands of VMs at once. This solution becomes particularly challenging if the VDA footprint for DR is anticipated to run into the hundreds or thousands of instances. Cloud providers tend to maintain bulk capacity for various instance sizes on-hand; however, this provider can vary from moment to moment. If a disaster affecting a geographical area occurs, there can be contention from other tenants also requesting on-demand capacity.
Key questions that need to be answered that can influence decisions:
- Is always 100% DR capacity required?
- Do we need to host critical workloads only (that is, only subset of production)?
- Is it viable to scale out at the time of DR? If so, have the use cases been prioritized by DR Tiers to better understand the varying RTOs of each use case to support a phased scale out of capacity?
- Can we scale up the OS instances supporting app or hosted shared desktop use cases to save on provisioning time and power off these instances to conserve operating costs?
Recommendations
Citrix recommends first engaging with your cloud provider to determine the viability of powering on the anticipated capacity within the RTO timeframe and if it can be met with on-demand instances or not. To hedge against capacity availability limitations for VDAs in a DR scenario, Citrix recommends provisioning VDAs across as many availability zones as possible. At large scales, it can be worthwhile provisioning across various cloud regions, and adjusting the architecture accordingly. Some cloud providers have suggested employing varying sizes of VM instance types to further mitigate VM exhaustion. Where possible, it would be prudent to pre-provision VDA instances and keep them offline and update them regularly. Provisioning is a resource and time intensive process and scaling out VDA DR capacity on-demand can be expedited to a degree by pre-provisioning. If the organization has little appetite for capacity availability risk, it can require applying reserved or dedicated compute capacity and budgeting accordingly to guarantee resource availability. It is possible to combine on-demand and reserved\dedicated models by referencing the DR recovery tier wherein certain use cases can require VDAs to be immediately available, while others can have the flexibility to be recovered over a longer RTO of several days or weeks if they are less critical to sustaining the business.
Consideration – Application and User Data
Impact Areas
Cost Availability Performance
Details
The location of user data and application back-ends can have a notable impact on performance and sometimes, availability of the Citrix DR environment. Some customer scenarios use a multi-data center DR approach where not all application back-ends or user data such as home and departmental drives cannot be recovered to cloud alongside Citrix. This gap can result in unanticipated latency which can impact the performance or even functionality of the applications. From a throughput perspective this gap can add further strain to available network and security appliance bandwidth.
Recommendations
Where possible, keep application and user data local to the Citrix platform in DR to maintain performance as optimal as possible by reducing latency and bandwidth demands across the WAN.
Disaster Recovery Planning for Citrix Cloud
There are several notable differences between on-prem or “traditional” deployment of Citrix Virtual Apps and Desktops (CVAD), vs. the Citrix Virtual Apps and Desktops Service (CVADS) provided by Citrix Cloud regarding DR planning:
- Citrix manages most control components for the partner/customer, removing significant DR requirements for the Citrix Site and its components from their responsibility.
- The deployment of a DR environment for Citrix resources merely requires a customer to deploy Citrix Cloud Connectors in the recovery “Resource Location”, and optionally StoreFront and Citrix ADCs for Citrix Gateway.
- Citrix Cloud’s unique service architecture is geographically redundant and resilient by design.
- Access tier DR is not required if using Citrix Workspace and Citrix Gateway services.
Beyond these core differences, many of the DR considerations from prior sections still require partner/customer planning, as they retain responsibility for the Citrix VDAs, user data, application back-ends, and Citrix access tier if Citrix Gateway Service and Citrix Workspace service are not used from Citrix Cloud.
This section covers key topics to assist customers in defining an appropriate DR strategy for Citrix Cloud.
CVADS Simplifies Disaster Recovery
Below is a typical conceptual diagram outlining the conceptual architecture of CVADS, in addition to the separation of responsibility for Citrix-managed components and partner/customer-managed components. Not illustrated here are the WEM, Analytics, and Citrix Gateway “Services” which are elective Citrix Cloud components related to CVADS which would fall under “Managed by Citrix”.

As illustrated in the diagram, a significant portion of Control components requiring recovery decisions fall under Citrix’s management scope. Being a cloud-based service, the CVADS architecture is highly resilient within theCitrix Cloud region. It is part of Citrix Cloud’s “Secret Sauce” and considered withinCitrix Cloud’s SLAs.
Service availability management responsibilities are as follows:
- Citrix.Control Plane and access “services” if in use (Workspace, Citrix Gateway Service).
- Customer.Resource Location components including Cloud Connectors, VDAs, application back-ends, infrastructure dependencies (AD, DNS, and so on), and access tier (StoreFront, Citrix ADCs) if not using Citrix Cloud access tier.
Customers gain the following advantages regarding disaster recovery on CVADS:
- Lower administrative burden due to fewer components to manage, and fewer independent configurations to replicate and maintain between locations.
- Reduced chances of human error and configuration discrepancies between Citrix deployments due to the centralized configuration of the “Citrix Site” in the Cloud.
- Streamlined operations due to simplification in resource management for production and disaster recovery deployments due to fewer Citrix Sites and components to be configured and maintained, no access tier to manage between locations (optional), and less complex disaster recovery logic for Citrix resources.
- Reduced operational costs with fewer server components to deploy and maintain and gain a single pane of glass view of environment trends across deployments through the centralization of the monitoring database.
CVADS Disaster Recovery Considerations
Although many components for recovery planning are removed from the customer’s scope of management, customers remain accountable the planning and management of DR and high availability (optional) for the components located within the Resource Location.
The most significant difference in how we address availability comes down to how we interpret and configure Resource Locations. Within CVADS itself, Resource Locations are presented asZones. WithZone Preferencewe can manage failover between Resource Locations based on the logic we specify. Using Zone Preference within a traditionally deployed CVAD Site would be considered a high-availability design but not a valid DR design. In the context of Citrix Cloud, this option is a valid DR solution.
Most of theDisaster Recovery Optionsdiscussed earlier apply to CVADS so there are numerous options to fit organizational recovery goals and budgets.
When planning DR for Citrix Cloud’s CVADS service, several key guiding principles from an infrastructure planning perspective needs to be understood:
- Resource Locations.Production and DR locations are set up as independent Resource Locations in Citrix Cloud.
- Cloud Connectors.Each Resource Location must have a minimum of two Cloud Connectors deployed. For clarity, Cloud Connectors are not a component which must be “recovered” manually or automatically during a DR event. They must be deemed “hot standby” components and kept online within each location.
- Customer-Managed Access Controllers (Optional).Customers can elect to deploy their own Citrix ADCs for Citrix Gateway and StoreFront servers and not consume Citrix Workspace or Citrix Gateway Service for several reasons. These can include:
- Custom authentication flows
- Increased branding capabilities
- Greater HDX traffic routing flexibility
- Auditing of ICA connections and integration into SIEM platforms
- Ability to continue to operate if the Cloud Connector’s connection to Citrix Cloud is severed, by using the Local Host Cache function of the Cloud Connectors with StoreFront
As with the Cloud Connectors, it is recommended to keep StoreFront and Citrix Gateway components deployed as “hot standby” in the recovery location and not recovering them during a DR event.
Operation Considerations
Maintaining the DR platform is essential to maintaining its integrity to avoid unforeseen issues when the platform is required. The following guidelines are recommended regarding operating and maintaining the DR Citrix environment:
- The Citrix DR Platform is Not Non-Prod.客户提供一个“热备份”环境tempted to cut corners and treat DR as a test platform. This treatment negatively impacts the integrity of the solution. In fact, DR would likely be the last platform to promote changes to, to ensure its utility is not affected in event maintenance went catastrophically wrong in a manner that was not exhibited in non-prod environments.
- Patching and Maintenance.Routine maintenance in lock-step with production when using “hot standby” Citrix platforms is essential to maintaining a functional DR platform. Keeping DR in sync with production with regards to OS, Citrix product, and application patches are important. To mitigate risk, allowing several days to a week between patching production and patching DR is suggested.
- Periodic Testing.Regardless of whether DR involves replication of production to a recovery facility or the use of “hot standby” environments, it is important to periodically test (twice a year or more is ideal) the DR plan to ensure the teams are familiar with recovery processes and any flaws in the platform or workflows are identified and remediated.
- Capacity Management.True for both Active-Passive and Active-Active “always on” Citrix environments, capacity or use case changes in production must be considered for DR as well. Especially when Active-Active models are used, it is easy for resource utilization to increase beyond say, a 50% steady-state utilization threshold of resources at each environment, only for a DR event to occur and the surviving platform becoming overwhelmed and either performing poorly or failing due to the overload. Capacity can be reviewed monthly or quarterly.
Summary
We have covered a fair bit of ground on the topic of disaster recovery in Citrix. The following points summarize the core messages and takeaways of this guide for architects and customers alike to consider when planning their Citrix recovery strategy:
- 理解业务需求和技术logical capabilities of a customer environment influences the disaster recovery strategy required for Citrix. The recovery strategy chosen can align to business objectives.
- High availability is not synonymous with disaster recovery. However, disaster recovery can include high availability.
- Sharing administrative boundaries between physical locations does not constitute a disaster recovery solution.
- Developing a disaster recovery tiering classification for an organization’s technology portfolio provides visibility, flexibility, and potential cost savings when developing a recovery strategy.
- RTO requirements for the Citrix infrastructure or the applications that are hosted on Citrix, is the most significant influencing factor to which disaster recovery design is needed. A shorter RTO often requires a higher solutions cost.
- Disaster recovery architectures for Citrix which do not employ a “hot” disaster recovery platform presents limitations into technologies a customer can use, such as Citrix MCS, ADC, and Provisioning.
- 灾难恢复策略Citrix需要肌萎缩性侧索硬化症o consider the recovery and recovery time of user data and application back-ends. Citrix can be engineered to recover rapidly, however users can nonetheless be unable to work if application and data dependencies are not available in a similar timeframe.
- Disaster recovery in cloud environments possesses their own considerations not present in on-premises environments which organizations must review to avoid unforeseen bottlenecks or operational impacts when invoking disaster recovery in cloud environments.
- It is imperative that disaster recovery components are kept up-to-date to match production updates and configurations to maintain the integrity of the platform.
- Platforms that use an active-active configuration for Citrix between locations must be mindful of capacity monitoring to ensure in the event of a disaster, sufficient resources are available to support the projected load at one or more surviving locations.
- Customers must test their disaster recovery plan for Citrix periodically to validate its operation and ability to serve its core purpose.
- Citrix Virtual Apps and Desktops Service significantly simplifies many aspects of the DR architecture, and allows Resource Location redundancy via Zone Preference configuration.
Sources
The goal of this article is to assist you with planning your own implementation. To make this task easier, we would like to provide you with source diagrams that you can adapt for your own needs:源图.
In this article
- Overview
- Business Requirements
- Misconceptions on Disaster Recovery (DR) Design
- Disaster Recovery (DR) vs. High Availability (HA)
- Disaster Recovery Tier Classifications
- Disaster Recovery Options
- Recovery Option - Recover from Offline Backup
- Recovery Option - Recover via Replication
- Recovery Option - Replication with Automated Recovery
- Recovery Option – Hot Standby (Active-Passive) with Manual Failover
- Recovery Option – Hot Standby (Active-Passive) with Automated Failover
- Recovery Option – Active-Active with Automated Failover
- Disaster Recovery in Public Cloud
- Disaster Recovery Planning for Citrix Cloud
- Operation Considerations
- Summary
- Sources