
Designentscheidung: Planung der Notfallwiederherstellung
Übersicht
Dieses Handbuch unterstützt die Planung von Business Continuity (BC) und Disaster Recovery (DR) Architektur sowie Überlegungen für On-Prem- und Cloud-Bereitstellungen von Citrix Virtual Apps and Desktops. DR ist an und für sich ein bedeutendes Thema in seiner Breite. Citrix erkennt an, dass dieses Dokument kein umfassender Leitfaden für die gesamte DR-Strategie ist. Es berücksichtigt nicht alle Aspekte der DR und nimmt manchmal eine eher Laienperspektive auf verschiedene DR-Konzepte ein.
In diesem Handbuch werden die folgenden Überlegungen behandelt, die erhebliche Auswirkungen auf die Citrix Architektur eines Unternehmens haben, und entsprechende Architekturleitfäden enthalten:
- Geschäftliche Anforderungen
- Disaster Recovery vs. Hohe Verfügbarkeit
- Klassifizierung der Disaster Recovery-Stufe
- Optionen für die Notfallwiederherstellung
- Disaster Recovery in der Cloud
- Überlegungen zur Bedienung
Geschäftliche Anforderungen
Ausrichtung auf die “Business Layer” der Citrix Entwurfsmethodik, Erfassung klarer Geschäftsanforderungen und bekannter Einschränkungen für die Wiederherstellung von Service. Die Dokumentation dieser Elemente ist der Ausgangspunkt für die Entwicklung eines Wiederherstellungsplans für Citrix. Dieser Schritt trägt dazu bei, Klarheit über den Umfang zu schaffen und eine Richtung für die DR-Strategie zu geben, die am besten geeignet ist, die geschäftlichen und funktionalen Anforderungen und Einschränkungen zu erfüllen.
Im Folgenden finden Sie einige Beispiele für nützliche Fragen, die diskutiert werden sollten. Diese Fragen werden im AbschnittDisaster Recovery-Optionenim Hinblick darauf, wie sie sich auf ein Citrix DR-Design auswirken, ausführlicher erörtert:
- Backupstrategie und Recovery Time Objective (RTO).Welche Backup-Strategie wird heute für Server verwendet? Backup-Häufigkeit? Aufbewahrungsfrist? Offsite-Speicher? Geprüft? Muss die Citrix-Plattform im Katastrophenfall sofort verfügbar sein oder innerhalb eines bestimmten Zeitraums online geschaltet werden? (Siehe Klassifizierungen der Disaster Recovery-Stufen). Es lohnt sich, Anwendungs-Backends, mit denen sich von Citrix gehostete Apps verbinden, in die Diskussion einzubeziehen, um die Erwartungen aufeinander abzustimmen
- Recovery Point Objective (RPO).Welcher Grad an Datenverlust wird für RPO als tolerierbar für DR angesehen, der je nach Infrastrukturkomponente oder Datenklassifizierung variieren kann? Wie alt können die wiederhergestellten Daten für den Dienst sein? 0 Minuten? Eine Stunde? Einen Monat? Im Kontext der Citrix Infrastruktur kann diese Überlegung nur für Datenbankänderungen und Benutzerdaten (Profile, Ordnerumleitung usw.) gelten. Wie bei RTO lohnt es sich, die Anwendungs-Backends für von Citrix gehostete Apps in die Diskussion einzubeziehen.
- Umfang der Wiederherstellung.Diese Überlegung umfasst nicht nur die Citrix Infrastruktur, sondern kann Benutzerdaten oder wichtige Anwendungsserver umfassen, mit denen Citrix gehostete Anwendungsclients eine Schnittstelle herstellen. Es ist wichtig zu ermitteln, ob es einen Unterschied zwischen der Zeit für die Wiederherstellung der Citrix-Plattform und der Zeit für die Wiederherstellung von auf Citrix gehosteten Anwendungen geben wird. Das Zeitdelta kann einen Ausfall verlängern, da nur ein Teil der Lösung online ist.
- Anwendungsfälle.Citrix-Plattformen bedienen häufig zahlreiche Anwendungsfälle, die jeweils unterschiedliche geschäftliche Kritikalität aufweisen. Deckt die Wiederherstellung alle Citrix Anwendungsfälle ab? Oder wichtige Anwendungsfälle, von denen der betriebliche Erfolg des Unternehmens vollständig abhängt. Die Antwort hat einen großen Einfluss auf das Infrastruktur-Scoping und die Kapazitätsprognosen. Die Segmentierung und Priorisierung von Anwendungsfällen wird empfohlen, um die Aktivierung von DR zu unterteilen, wenn es sich um eine neue Funktion für die Citrix-Umgebung handelt.
- Fähigkeiten.Gibt es wichtige Funktionen, die nicht in die DR aufgenommen werden müssen, um die Kosten zu senken? Ein Beispiel für diese Funktion wäre die Verwendung von persistenten Desktops im Vergleich zu nicht persistent; einige VDI-Anwendungsfälle, die von gehosteten Shared Desktops oder sogar bestimmten Anwendungssolos bedient werden können. Kunden haben zeitweise angegeben, dass Komponenten-Redundanz (ADCs, Controller, StoreFront, SQL usw.) in DR. Solche Entscheidungen können als Risiko angesehen werden, wenn ein längerer Produktionsausfall vorliegt.
- Bestehende DR.Gibt es eine bestehende DR-Strategie oder einen Plan für andere Citrix-Umgebungen und andere Infrastrukturdienste? Stellt es sich in neue routingfähige Subnetze oder in eine “Blase” -Spiegelung der Produktionsnetzwerke wieder her? Die Antwort kann dazu beitragen, die aktuellen DR-Ansätze, -Werkzeuge oder den Vorrang sichtbar zu machen.
- Technologische Fähigkeiten.Diese Überlegung kann die endgültige Recovery-Strategie für Citrix nicht diktieren, es ist jedoch wichtig zu verstehen:
- Recovery:Welche Speicherreplikationstechnologien, VM-Recovery-Technologien (VMware SRM, Veeam, Zerto, Azure Site Recovery (ASR) usw.) sind innerhalb des Unternehmens verfügbar? Einige Citrix Komponenten neben Citrix Abhängigkeiten können sie verwenden.
- Citrix:Welche Citrix-Technologien werden für die Image-Verwaltung und den Zugriff verwendet? Einige Komponenten können sich für bestimmte Erholungsstrategien nicht gut eignen. Nicht persistente Umgebungen, die von MCS oder PVS verwaltet werden, sind aufgrund ihrer engen Integration in Speicher und Netzwerk schlechte Kandidaten für VM-Replikationstechnologien.
- Kritikalität der Daten.Werden Benutzerprofile oder Benutzerdaten als kritisch für die Wiederherstellung angesehen? Dauerhafte VDIs? Wenn diese Daten beim Aufruf von DR nicht verfügbar sind, würde dies erhebliche Auswirkungen auf die Produktivität haben? Oder kann ein nicht persistentes Profil oder VDI als temporäre Lösung verwendet werden? Diese Entscheidung kann die Kosten und die Komplexität der Lösungen in die Höhe treiben.
- Arten von Katastrophen.Diese Entscheidung ist ziemlich bedeutend, kann aber auch durch einen BC- oder DR-Plan des Unternehmens festgelegt werden. Diese Anforderung diktiert oft den Wiederherstellungsort. Ist die Strategie darauf ausgelegt, die Wiederherstellung von Diensten nur auf Anwendungsebene zu ermöglichen? Zwischen Hardware-Racks? Innerhalb einer Metro-Lage? Zwischen zwei Regionen? Zwei Länder? Innerhalb einer Cloud-Anbieterregion oder der Infrastruktur eines gesamten Cloud-Anbieters (multiregional)?
- Clientbenutzer.Wo befinden sich die Benutzer, die auf die Dienstleistungen in der Produktion zugreifen? Diese Entscheidung kann sich darauf auswirken, wo der Service wiederhergestellt wird, einschließlich der Netzwerkkonnektivität des Unternehmens, die während eines DR-Ereignisses manuelle Änderungen erfordern kann. Darüber hinaus diktiert die Antwort Überlegungen zu den Zugriffstufen.
- Netzwerkbandbreite.Wie viel Datenverkehr (ICA, Anwendung, Dateidienste) verbraucht jede Benutzersitzung im Durchschnitt? Diese Entscheidung gilt sowohl für Cloud- als auch für die lokale Wiederherstellung.
- Fallback (oder Failback).Verfügt das Unternehmen bereits über Pläne, wie die Produktion wieder in Betrieb genommen werden kann, sobald die DR-Situation gelöst ist? Wie erholt sich die Organisation in einen normalen Zustand? Wie werden neue Daten, die in der DR erstellt werden können, mit der Produktion in Einklang gebracht und konsolidiert?
Einschränkungen schränken die BC/DR-Entwurfsoptionen oder deren Konfigurationen ein. Sie kommen in vielen Formen vor, können aber Folgendes beinhalten:
- Gesetzliche Vorschriften oder Unternehmensrichtlinien.Diese Entscheidung kann vorschreiben, welche Technologien für die Replikation oder Recovery verwendet werden können oder nicht, wie sie verwendet werden, RTO oder Mindestabstand zwischen den Einrichtungen.
- Infrastruktur.Gibt es eine Richtlinie über die Art der zu verwendenden Hardware, die verfügbare Netzwerkbandbreite usw.? Diese Überlegungen können sich auf RPO-Überlegungen auswirken oder sogar Risiken darstellen. Beispielsweise können unterdimensionierte Firewalls oder Netzwerk-Pipes in der DR letztendlich zu Ausfällen führen, da Netzwerkabhängigkeiten die DR-Arbeitslast nicht bewältigen können. Oder im Falle von Computing können unterdimensionierte Hypervisor-Hosts oder die Verwendung verschiedener Hypervisoren vollständig Auswirkungen auf die Optionen haben. In Bezug auf das Netzwerk, wenn der Wiederherstellungsstandort bei der Wartung des WAN im Vergleich zur Produktion eine eingeschränktere Netzwerkdurchsatzfähigkeit aufweist. In Cloud-Umgebungen, insbesondere bei der Skalierung auf Tausende von Sitzen, kann dieses potenzielle Risiko aufgrund von Einschränkungen des Komponentendienstes wie virtuellen Firewalls, VPN-Gateways und Cloud-zu-WAN-Uplinks (AWS Direct Connect, Azure ExpressRoute, Google Cloud Interconnect usw. am).
- Budget.DR-Lösungen sind mit Kosten verbunden, die mit den Projektbudgets in Konflikt geraten können. In den meisten Fällen sind die Kosten umso höher, je kürzer die RTO ist.
- Geografie.Wenn eine benannte DR-Einrichtung identifiziert wurde, müssen Überlegungen wie die Latenz von der Produktion zu DR-Einrichtungen zusätzlich zu den Benutzern, die eine Verbindung zur DR herstellen, verstanden werden.
- Datenresidenz oder Datenklassifizierung.Diese Entscheidung kann Optionen in Bezug auf Gebietsschemas und Technologien oder Wiederherstellungsmethoden einschränken.
- Cloud-Wiederherstellung.Gibt es ein Mandat für die Wiederherstellung der Infrastruktur in der Cloud im Vergleich zu einer lokalen Einrichtung?
- Bereitschaft von Anwendungen.Verfügt die auf Citrix gehosteten Anwendungen mit Back-End-Abhängigkeiten über einen BC/DR-Plan und wie werden die RTOs an die Citrix Ziel-RTO ausgerichtet? Citrix kann für eine schnelle Recovery konzipiert werden, aber wenn Kernanwendungen keinen Wiederherstellungsplan oder einen mit einem erweiterten RTO haben, hat dieses Risiko wahrscheinlich Auswirkungen auf die Nützlichkeit der Citrix-Plattform in DR.
- Netzwerk-Sicherheit.Verfügt die Organisation über Sicherheitsrichtlinien, die festlegen könnten, welche Verkehrssegmente bei der Übertragung verschlüsselt werden müssen? Ist diese Überlegung abhängig von der durchlaufenen Netzwerkverbindung unterschiedlich? Die Antwort könnte in DR-Szenarien die Verwendung von SSL VDA, ICA-Proxy, GRE oder IPsec-VPN-Einkapselung des ICA-Verkehrs erfordern, wenn sich die Netzwerkflüsse für DR von der Produktion unterscheiden.
Missverstandnisse贝灾难恢复(DR)设计n
Eines der häufigsten Missverständnisse bei Citrix DR-Designs ist die Vorstellung, dass eine einzelne Steuerungsebene, die sich über zwei Rechenzentren erstreckt, DR darstellt. Das tut es nicht. Ein einzelner Citrix Standort oder PVS Farm, die Rechenzentren umfasst, auch wenn sie in der Nähe sind, stellt ein Design mit hoher Verfügbarkeit dar, jedoch kein DR-Design. Einige Kunden entscheiden sich für diesen Weg als Geschäftsentscheidung, bei der die vereinfachte Verwaltung über die DR-Funktion bewertet werden. StoreFront-Servergruppenwerden nur zwischen gut verbundenen Rechenzentren (niedrige Latenz) unterstützt. In ähnlicher Weise hat PVS die Latenzmaxima dokumentiert, die bei der Bereitstellung in Rechenzentren zu berücksichtigen sind, wie inCTX220651beschrieben.
Das folgende Diagramm ist ein Beispiel für eine Multi-Datacenter HA Citrix Architektur, die jedoch aufgrund der zuvor erwähnten Begründung keine DR-Plattform ist. Diese Referenzarchitektur wird von Kunden verwendet, die zwei physisch getrennte Rechenzentrumseinrichtungen aufgrund ihrer Nähe zueinander und der Interkonnektivität mit geringer Latenz und hoher Bandbreite als ein einziges logisches Rechenzentrum behandeln. Ein DR-Plan und eine Umgebung für Citrix würden weiterhin empfohlen, da diese Architektur die Anforderungen von DR oder HA wahrscheinlich nicht erfüllen würde.

Zusätzlich zu der oben genannten HA-Konzeptreferenz sind auf Zonen basierende HA-Architekturen für Kunden verfügbar, die geoübergreifende Redundanz bereitstellen möchten, die Plattform jedoch nicht vollständig wiederherstellbar sein müssen. Das Zonenkonzept aus der Legacy-IMA-Architektur (XenApp 6.5 und niedriger) wurde für FMA überarbeitet und in XenDesktop 7.7 mit großen Verbesserungen in 7.11 wieder eingeführt und ermöglicht verschiedene Funktionen für die Redundanz an Standorten, die Herausforderungen für Bereitstellungen mit mehreren Standorten lösen können.
In einer Site-Architektur, die die Funktion “Zonenpräferenz“ (7.11 und höher) verwendet, werden identische Citrix-Ressourcen über mehrere Zonen hinweg bereitgestellt und in einer einzigen Bereitstellungsgruppe zusammengefasst. Die Zonenpräferenz (mit der Möglichkeit, auf andere Zonen für eine bestimmte Ressource zurückzuteilen) kann basierend auf der Anwendung, der Heimatzone des Benutzers oder dem Benutzerstandort gesteuert werden. Weitere Informationen zu diesem Thema finden Sie unterInterna der Zonenpräferenz. Die Funktionzur automatischen Aktualisierung der VDA-Registrierung(eingeführt in XenDesktop 7.6) ermöglicht es VDAs, eine lokal zwischengespeicherte, aktuelle Liste aller Controller innerhalb einer Site zu verwalten. Mit dieser Funktion können VDAs innerhalb der Satellitenzone über die Registrierung bei VDAs in der primären Zone fehlschlagen, falls ihre lokalen Delivery Controller oder Cloud Connectors in ihrer lokalen Zone nicht verfügbar sind. StoreFront-Servergruppen sind an jedem Zonenstandort vorhanden, da Benutzer weiterhin auf Ressourcen von ihrer lokalen Zugriffsstufe zugreifen können, falls die primäre Zone nicht verfügbar ist.

Im Gegensatz zu diesen unterstützten HA-Optionen zeigt das folgende Diagramm nicht unterstützte oder schlecht beratene Komponentenarchitekturen, die sich über geografisch entfernte Rechenzentren oder Cloud-Regionen erstrecken. Diese Diagramme bieten aufgrund des Abstands und der Latenz zwischen Komponenten weder effektive HA noch DR. Probleme mit der Plattformstabilität können auch aufgrund von Bedenken hinsichtlich der Latenz bei einer solchen Bereitstellung auftreten. Darüber hinaus stimmt die Ausdehnung der Verwaltungsgrenzen zwischen Standorten nicht mit den DR-Prinzipien überein. Wir haben in der Vergangenheit ähnliche Konzeptentwürfe von Kunden gesehen.

Ein weiteres weit verbreitetes Missverständnis ist die Tiefe der Überlegung, die eine Citrix DR-Lösung beinhalten kann. Citrix Virtual Apps and Desktops ist im Kern in erster Linie eine Präsentations- und Bereitstellungsplattform. Die Citrix Steuerungsebene hängt von anderen Komponenten (Netzwerk, SQL, Active Directory, DNS, RDS-CALs, DHCP usw.) ab, deren eigenes Verfügbarkeits- und Recovery-Design die DR-Anforderungen der Citrix-Plattform erfüllt. Jede gemeinsame administrative Domäne von Technologien, von denen Citrix abhängig ist, kann sich auf die Wirksamkeit der Citrix DR-Lösung auswirken.
Von ähnlicher Bedeutung und gelegentlich nicht vollständig von Kunden berücksichtigt werden, sind Überlegungen zur Wiederherstellung von Dateiservices (Benutzerdaten und Geschäftsdaten auf Freigaben usw.) und Anwendungs-Backends, mit denen Citrix gehostete Anwendungen und Desktops interagieren. Wenn Sie den früheren Punkt der Anwendungsbereitschaft referenzieren, kann eine Citrix DR-Plattform so konzipiert werden, dass sie in kurzen Zeitspannen wiederhergestellt werden kann. Wenn diese Kern-Anwendungsfallabhängigkeiten jedoch keinen Wiederherstellungsplan mit RTO ähnlich wie Citrix oder gar keinen Wiederherstellungsplan besitzen, kann dieser Plan die erfolgreiche Ausfälle von Citrix in der DR wie erwartet beeinträchtigen, aber Benutzer können ihre Auftragsfunktionen nicht ausführen, da diese Abhängigkeiten nicht verfügbar sind. Nehmen wir zum Beispiel ein Krankenhaus, das seine EMR-Kernanwendung auf Citrix hostet. Ein DR-Ereignis tritt auf und Citrix schlägt auf eine “Always on” Citrix Plattform in der DR fehl und Benutzer stellen eine Verbindung her, aber die EMR-Anwendung wird auf mehr manuelle Weise wiederhergestellt, was Stunden oder Tage dauern kann. Das klinische Personal wäre in dieser Zeit wahrscheinlich gezwungen, Offline-Prozesse (Stift und Papier) zu verwenden. Ein solches Ergebnis kann nicht mit der allgemeinen Erwartung des Unternehmens nach Erholungszeit oder Benutzererfahrung übereinstimmend sein.
Im nächsten Abschnitt wird DR vs. HA genauer.
Disaster Recovery (DR) vs. Hochverfügbarkeit (HA)
HA verstehen vs. DR ist entscheidend für die Ausrichtung auf die Anforderungen des Unternehmens und die Erreichung der Wiederherstellungsziele. HA ist nicht gleichbedeutend mit DR, aber DR kann HA verwenden. In diesem Handbuch werden HA und DR wie folgt interpretiert:
- HA gilt als Fehlertoleranz für eine Dienstleistung. Ein Dienst kann mit minimaler Unterbrechung für einen Benutzer ein Failover auf ein anderes System durchführen. Die Lösung kann so einfach sein wie eine Cluster- oder Lastausgleichsanwendung für eine komplexere aktive oder Standby-“heiße” oder “Always on” -Infrastruktur, die die Produktionskonfigurationen widerspiegelt und immer verfügbar ist. Failover wird in diesen Konfigurationen tendenziell automatisiert und kann auch als “georedundante” Bereitstellung bezeichnet werden.
- DR befasst sich in erster Linie mit der Wiederherstellung von Diensten (aufgrund eines erheblichen Ausfalls auf App-Ebene oder eines katastrophalen physischen Ausfalls des Rechenzentrums) an einem alternativen Rechenzentrum (oder einer Cloud-Plattform). DR beinhaltet tendenziell automatisierte oder manuelle Wiederherstellungsprozesse. Schritte und Verfahren zur Orchestrierung der Wiederherstellung werden dokumentiert. Es befasst sich nicht mit Redundanz oder Fehlertoleranz des Dienstes und ist im Allgemeinen eine Strategie mit umfassenderem Umfang, die mehreren Arten von Fehlern standhält.
Während HA in der Regel in Designspezifikationen und Lösungsbereitstellung eingebettet ist, befasst sich DR hauptsächlich mit der Orchestrierungsplanung von Personal- und Infrastrukturressourcen, um die Wiederherstellung des Dienstes aufzurufen.
萤石HA beinhalten博士吗?农协。毛皮unternehmenskritische IT-Services in Unternehmen ist dieses Konzept üblich. Nehmen wir zum Beispiel das zweite Beispiel in der obigen HA-Beschreibung in Verbindung mit einer angemessenen Wiederherstellung anderer nicht mit der Lösung verbundener Komponenten, die nicht von Citrix stammen, würde als hochverfügbare DR-Lösung angesehen, bei der ein Dienst (Citrix) ein Failover zu einem gegnerischen Rechenzentrum durchführt. Diese spezielle Architektur kann als Active-Passive oder Active-Active in verschiedenen Multi-Site-Iterationen implementiert werden, z. B. Active-Passive für alle Benutzer, Active-Active, wobei Benutzer ein Rechenzentrum gegenüber einem anderen bevorzugen, oder Aktiv-Aktiv, wobei Benutzer ohne Präferenz zwischen zwei Rechenzentren Lastenausgleich haben. Es ist wichtig zu beachten, dass beim Entwurf solcher Lösungen die Standby-Kapazität kontinuierlich berücksichtigt, berücksichtigt und die Last überwacht werden muss, um sicherzustellen, dass die Kapazität für die Aufnahme von DR verfügbar bleibt, wenn dies erforderlich ist.
Es ist auch wichtig, dass DR-Komponenten mit der Produktion auf dem neuesten Stand gehalten werden, um die Integrität der Lösung zu erhalten. Diese Aktivität wird häufig von Kunden übersehen, die eine solche Lösung mit den besten Absichten entwerfen und bereitstellen, dann mehr Plattformressourcen in der Produktion verbrauchen und vergessen, die verfügbare Kapazität zu erhöhen, um die DR-Integrität der Lösung zu erhalten.
Im Zusammenhang mit Citrix würde das Überspannen von Citrix Verwaltungsdomänen (Citrix Site, PVS-Farm usw.) zwischen zwei Rechenzentren wie zwei geolokalisierten Einrichtungen gemäß denveröffentlichten Leitlinienkeine DR darstellen und für einige Komponenten wie StoreFront-Servergruppen. In ähnlicher Weise würde eine solche Bereitstellung aufgrund der Beschränkungen der Datenbanklatenz von PVS lautveröffentlichten Leitlinienwahrscheinlich auch nicht unterstützt. Unterstützbarkeitsbeschränkungen zwischen Geos erstrecken sich manchmal auch auf das Citrix Site- und Zone-Design, aufgrund der Latenzmaxima zwischen Satelliten-Controllern und den Datenbanken gemäßveröffentlichter Anleitung.
达有Citrix Komponenten Abhangigkeiten wie Datenbanken gemeinsam nutzen, würde die Ausdehnung von Verwaltungsgrenzen zwischen den beiden Rechenzentren nicht vor mehreren wichtigen Ausfallszenarien schützen. Wenn Datenbanken beschädigt würden, würde sich die Ausfalldomäne auf die Anwendungsdienste in beiden Einrichtungen auswirken. Um eine HA Citrix-Lösung als ausreichend für DR anzusehen, empfehlen wir, dass die zweite Einrichtung keine wichtigen Abhängigkeiten oder Verwaltungsgrenzen gemeinsam nutzt. Erstellen Sie beispielsweise separate Sites, Farmen und Servergruppen für jedes Rechenzentrum in der Lösung. Indem wir eine Wiederherstellungsplattform so unabhängig wie möglich machen, reduzieren wir die Auswirkungen von Ausfällen auf Komponentenebene, die sich auf Produktions- und DR-Umgebungen auswirken. Diese Überlegung geht auch über Citrix hinaus, und die Verwendung verschiedener Dienstkonten, Dateidienste, DNS, NTP, Hypervisor-Management, Authentifizierungsdienste (AD, RADIUS usw.) zwischen Produktions- und DR-Umgebungen wird ebenfalls empfohlen, um einzelne Fehlerquellen zu reduzieren.
Klassifizierung der Disaster Recovery-Stufe
Tier-Klassifizierungen für DR sind ein wichtiger Aspekt der DR-Strategie eines Unternehmens, da sie Klarheit über die Anwendungs- oder Servicekritikalität bieten, die wiederum die RTO (und damit die Kosten für die Erreichung dieses Wiederherstellungsniveaus) bestimmt. Im Allgemeinen gilt: Je kürzer der RTO, desto höher sind die Kosten für die DR-Lösung. Die Möglichkeit, verschiedene Abhängigkeiten in verschiedene Klassifizierungen zu unterteilen (basierend auf Geschäftskritikalität und RTO), kann zur Optimierung kostensensibler DR-Fälle beitragen.
Im Folgenden法登您一张Reihe冯Beispielklassifizierungen der DR-Ebene, die als Referenz bei der Bewertung der Citrix Infrastrukturdienste, ihrer Abhängigkeiten und der auf Citrix gehosteten kritischen Anwendungen oder Anwendungsfälle (die mit VDAs verknüpft sind) dienen. DR-Stufen werden in Reihenfolge oder Wiederherstellungspriorität beschrieben, wobei 0 die kritischste ist. Organisationen werden ermutigt, eine DR-Tiering-Klassifizierung anzuwenden oder zu entwickeln, die auf ihre eigenen Wiederherstellungsziele und Klassifizierungsanforderungen abgestimmt ist.
Disaster Recovery Tier 0
Stufe 0 — Wiederherstellungsziele (Beispiele)
ziel4 der Erholungszeit: 0
Wiederherstellungspunkt-Ziel: 0
Stufe 0 — Beispiele für Klassifizierungen
Kern-IT-Infrastruktur
- Netzwerk- und Sicherheitsinfrastruktur
- Netzwerk-Links
- Hypervisoren und Abhängigkeiten (Rechner, Speicher)
Kern-IT-Services
- Active Directory
- DNS
- DHCP
- Dateidienste
- RDS-Lizenzierung
- Kritische Endbenutzerdienste (Citrix)
Tier 0 - Hinweise
Diese Klassifizierung bezieht sich hauptsächlich auf Kerninfrastrukturkomponenten. Diese Komponenten sind immer am DR-Standort verfügbar, da sie Abhängigkeiten für andere Ebenen und nicht in einem isolierten Netzwerksegment sind. Sie müssen neben ihren Produktionsäquivalenten bereitgestellt und gewartet werden. Wenn Citrix kritische Anwendungen hostet, wird es wahrscheinlich als Tier-0-Plattform angesehen. In solchen Szenarien wird die Citrix Infrastruktur “heiß” in DR.
Disaster Recovery Tier 1
Stufe 1 — Wiederherstellungsziele (Beispiele)
Ziel der Erholungszeit: 4 Stunden
Wiederherstellungspunkt-Ziel: 15 Minuten
Stufe 1 — Beispiele für Klassifizierungen
Kritische Anwendungen
- Websites und Web-Apps
- ERPs und CRM-Anwendungen
- Anwendungen für Geschäftsbereiche
Citrix-Anwendungsfälle
- Verwaltung
- Kundenservice oder Vertrieb
- IT-Technik und Support
一级- Hinweise
Anwendungen oder virtuelle Desktops, auf die das Unternehmen angewiesen ist, um die Kerngeschäftsaktivitäten auszuführen, sind in der Regel in dieser Ebene enthalten. Sie würden wahrscheinlich auch eine ähnliche “Hot Standby” -DR-Architektur wie Tier 0 verwenden oder von einer automatisierten Replikations- und Failover-Lösung profitieren. Bei der Bereitstellung in der Cloud müssen diespäter erörtertenÜberlegungen berücksichtigt werden, da sie sich auf die RTO-Ziele auswirken können.
Disaster Recovery Tier 2
Stufe 2 — Wiederherstellungsziele (Beispiele)
Ziel der Erholungszeit: 48 Stunden
Wiederherstellungspunkt-Ziel: 1 Stunde
Stufe 2 — Beispiele für Klassifizierungen
Nicht kritische Anwendungen Nicht kritische Citrix-Anwendungsfälle Benutzerdaten, die sich nicht auf die Funktionalität von Tier 1- oder Tier-0-Apps auswirken.
层2 -Hinweise
Anwendungen oder Anwendungsfälle, die für den Geschäftsbetrieb von entscheidender Bedeutung sind, deren kurzfristige Nichtverfügbarkeit jedoch wahrscheinlich keine schwerwiegenden finanziellen, Reputations- oder betrieblichen Auswirkungen haben wird. Diese Anwendungen werden entweder aus Backups wiederhergestellt oder mit der niedrigsten Priorität durch automatische Wiederherstellungstools wiederhergestellt.
Disaster Recovery Tier 3
Stufe 3 — Wiederherstellungsziele (Beispiele)
Ziel der Wiederherstellungszeit: 5 Tage
Wiederherstellungspunktziel: 8 Stunden
Stufe 3 — Beispiele für Klassifizierungen
Selten genutzte Anwendungen
Tier 3 - Hinweise
Anwendungen mit vernachlässigbaren Ausflüssen auf Ausfälle sind bis zu einer Woche nicht verfügbar. Diese Anwendungen werden wahrscheinlich aus Backups wiederhergestellt.
Disaster Recovery Tier 4
Stufe 4 — Wiederherstellungsziele (Beispiele)
Ziel der Wiederherstellungszeit: 30 Tage
Recovery Point Objective: 24 Stunden oder keine
Stufe 4 — Beispiele für Klassifizierungen
Nicht-Produktionsumgebungen
Tier 4 - Hinweise
Anwendungen, Infrastruktur und VDIs, deren Ausfälle sich ebenfalls vernachlässigbar auf den Geschäftsbetrieb auswirken und über einen längeren Zeitraum wiederhergestellt werden können. Sie können auch ein erweitertes RPO haben, oder überhaupt nicht, abhängig von ihrer Natur. Diese RPOs können aus Backups wiederhergestellt oder in der DR brandneu gebaut werden und gelten als die letzte zurückzufindende Stufe.
Warum ist die Tierklassifizierung für die Citrix DR-Planung wichtig?
Die Tierklassifizierung ist für Citrix aus folgenden Gründen wichtig:
- Wie wichtig ist die Citrix-Infrastruktur für den Geschäftsbetrieb? Es ist wichtig zu berücksichtigen, dass die Citrix Infrastruktur als kritisch eingestuft wird, wenn Citrix als wichtig erachtet wird, eine von ihr gehostete Anwendung jedoch als kritisch angesehen wird.
- Die Anwendungsfälle oder Kerngeschäftsanwendungen, die Citrix hostet; haben sie unterschiedliche DR-Tier-Klassifizierungen?
Bei der ersten Frage werden viele Citrix-Enterprise-Bereitstellungen aufgrund der Bereitstellung kritischer Apps oder Desktops in der Regel als Tier 0 klassifiziert; die “Always on” -Tier wie Netzwerk-, Active Directory-, DNS- und Hypervisor-Infrastruktur. Dieser Umstand ist jedoch nicht immer für jeden Citrix Anwendungsfall der Fall. Die Behandlung jedes Citrix Anwendungsfalls als Tier 0, wenn einige in Tier 1 oder höher fallen können, kann sich dies auf die Gesamtkosten und die Komplexität des DR-Prozesses auswirken.
Die zweite Frage betont die Klassifizierung nach Citrix-Anwendungsfall und verleiht ihrer Bedeutung am wichtigsten in Cloud-Umgebungen, auf diespäter ausführlicher eingegangenwird. In der Cloud gibt es erhebliche Kostenüberlegungen zwischen der Berücksichtigung von “Always on” Anwendungs- oder Desktop-Plattformen im Vergleich zu Anwendungen oder Desktops, die als weniger geschäftskritisch angesehen werden. Solche Überlegungen können auch die Anwendungs- oder Anwendungsfallisolation (Silos) in der Produktion beeinflussen, um die Flexibilität der Bereitstellung in einer DR-Plattform zu nutzen.
贝der Erstellung进行DR-Entwurfs毛皮Citrixt es sinnvoll, die Diskussion über den Anwendungsbereich von Citrix selbst hinaus zu bringen, um Erwartungen an Geschäftseinheiten zu setzen. Beispielsweise wird eine Citrix-Umgebung als “Always On” -Dienst betrachtet und in einem alternativen Rechenzentrum hochverfügbar gemacht. Die kritischen Anwendungs-Backends, von denen die gehosteten Anwendungen von Citrix abhängig sind, bleiben jedoch für mehrere Stunden nicht verfügbar, wenn die Wiederherstellung aufgerufen wird. Diese Lücke führt zu einer Disparität in der Wiederherstellungszeit zwischen den beiden Plattformen und kann während der Wiederherstellung eine irreführende Benutzererfahrung bieten. Citrix ist sofort verfügbar, aber wichtige Anwendungen sind nicht funktionsfähig. Die Festlegung von Erwartungen zu Beginn bietet allen Stakeholdern eine angemessene Sichtbarkeit darüber, wie die Erholungserfahrung aussehen kann. In einigen Situationen kann ein Kunde Citrix in der gegnerischen Einrichtung auf Hot Standby (immer aktiv) halten, aber das Failover der Zugriffsstufe manuell steuern, um Missverständnisse bei der Plattformverfügbarkeit zu vermeiden.
Optionen für die Notfallwiederherstellung
In diesem Abschnitt werden allgemeine Wiederherstellungsstrategien von Citrix beschrieben, einschließlich ihrer Vor- und Nachteile sowie wichtige Überlegungen. Andere Wiederherstellungsfunktionen oder Variationen der folgenden Themen für Citrix sind möglich. Dieser Abschnitt konzentriert sich auf einige der gebräuchlichsten. Darüber hinaus veranschaulicht dieser Abschnitt, wie die Antworten auf die frühzeitig dargestellten Kernfragen auf das DR-Design beeinflussen.
Die folgenden Fragethemen, die zu viele der früheren DR-Fragen korrelieren, haben folgende Auswirkungen auf das Design von Citrix DR:
- Backupstrategie und Recovery Time Objective (RTO).Wenn die Citrix Infrastruktur oder Anwendungen, die von Citrix bereitgestellt werden, als unternehmenskritisch angesehen werden, ist es wahrscheinlich, dass Citrix ein “Always on” -Modell einsetzen muss, bei dem sich in zwei oder mehr Rechenzentren eine Hot-Standby- oder Active-Active-Citrix-Infrastruktur befindet. Diese Architektur würde dazu führen, dass in jedem Rechenzentrum mehrere unabhängige Citrix-Steuerungsebenen erstellt werden (separate Citrix Standorte, ggf. PVS-Farmen, StoreFront-Servergruppen usw.). Das Überspannen der Steuerungsebenen für die Citrix Infrastruktur stellt keine DR dar (z. B. die Überspannungseinheit einer Site über Rechenzentren hinweg oder die Verwendung von Satellitenzonen). Dies tut dies, wenn das Unternehmen eine DR-Plattform für Citrix erwartet, die auf dieses Mandat einwirkt.
- Umfang der Wiederherstellung.Wenn Citrix in einer Hot-Standby-Kapazität (immer aktiv) in der DR bereitgestellt wird, die Backends der Kerngeschäftsanwendung jedoch beispielsweise 8 Stunden dauern, kann die Wiederherstellung nicht sinnvoll sein, ein automatisiertes Zugriffsstufen-Failover einzusetzen. Manuelles Failover der Zugriffsstufe kann angemessener sein.
- Anwendungsfälle.Wenn nur kritische Workloads oder Kernanwendungen in Citrix schnell wiederhergestellt werden müssen, um den Geschäftsbetrieb in einem DR-Szenario aufrechtzuerhalten, kann dieses Szenario die DR-Kosten aus Kapazitätsperspektive wahrscheinlich senken. Wenn mehrere Anwendungsfälle mit unterschiedlichen Prioritäten eine Wiederherstellung erfordern, kann die Klassifizierung der Wichtigkeit pro Anwendungsfall im Gegensatz zu den geschäftlichen Auswirkungen gemäß derzuvor diskutiertenRecovery-Tiering-Strategie die Kapazitätskosten nicht reduzieren, sondern den IT-Mitarbeitern einen gezielteren Satz von Wiederherstellungsprioritätsaufträgen bieten.
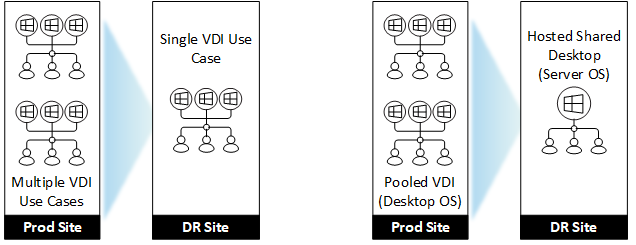
- Fähigkeiten.Wenn bestimmte Komponenten wie HDX Insight, Sitzungsaufzeichnung für den Betrieb der DR-Plattform nicht als kritisch erachtet werden, verringert ihr Weglassen in der DR-Umgebung eine gewisse Komplexität und Wartungsaufwand. Wenn viele Anwendungsfälle in einem DR-Szenario von einer einfacheren und generischeren Citrix Bereitstellungsoption in der DR bestehen können, kann dies auch die Komplexität und die Kosten reduzieren. Zum Beispiel die Verwendung eines Hosted Shared Desktops anstelle eines gepoolten VDI, wenn dies technisch machbar ist, oder die Zusammenfassung mehrerer Anwendungsfälle zu einem, sofern sie sich nicht nachteilig auf den Geschäftsbetrieb auswirken.
- Bestehende DR.Wenn die vorhandene DR-Strategie des Unternehmens beispielsweise Citrix und andere Anwendungsinfrastrukturen mithilfe von Tools zur Datenreplikation und -orchestrierung wiederherstellt, können die meisten Citrix Komponenten für dieses Modell geeignet sein. Wenn die Größe der Plattform und die Abhängigkeit von der Single-Image-Verwaltungstechnologie eine Anforderung für die Produktionsplattform ist, können solche Technologien oft nicht geeignet sein. Ein hybrider Ansatz einer Hot-Standby-Citrix-Plattform und möglicherweise die Replikation von Master-Images können angemessener sein.
- Kritikalität der Daten.Wenn Profile für die Wiederherstellung in der DR als kritisch erachtet werden, kann eine angemessene Replikationstechnologie erforderlich sein. Viele Unternehmen beschäftigen sich weniger mit Profilen in DR-Szenarien und akzeptieren, dass sie neu erstellt werden. Diese Überlegung gilt auch für Benutzerdaten, auf die in Citrix zugegriffen wird (Ordnerumleitung, zugeordnete Laufwerke); RPO und RTO für diese Daten können eine Geschäftsentscheidung sein. Wenn viele persistente VDIs als wichtig genug erachtet werden, um in der DR intakt zu bleiben (anstatt dass Benutzer ihre Software neu installieren müssen usw.), müssen diese VMs für die Replikation in Betracht gezogen werden, was zusätzliche Kosten für die Unterstützung der Wiederherstellung verursachen kann.
- Arten von Katastrophen.Das Ausmaß,民主党西奇静脉Kunde伏尔Fehlern schutzen möchte, kann verschiedene architektonische Veränderungen vorschreiben. Wenn der Kunde nur HA der Citrix Infrastruktur innerhalb des Rechenzentrums oder der Cloud-Region wünscht, kann diese Art von Katastrophe lediglich sicherstellen, dass die Managementkomponenten sowohl redundant sind als auch auf gegensätzlichen Infrastrukturen arbeiten. Beispielsweise verwendet eine Art von StoreFront-Serverpaar VMware Anti-Affinitätsregeln, um auf verschiedenen Hosts in einem Cluster oder auf verschiedenen Clustern vollständig innerhalb des Rechenzentrums oder möglicherweise als Teil verschiedener Verfügbarkeitssätze zu arbeiten. Für diese Situation ist es selten erforderlich, redundante Steuerungsebenen vollständig zu erstellen (z. B. mehrere Citrix Sites und StoreFront-Servergruppen). Wenn DR jedoch mehrere Rechenzentren unabhängig von der Region umfassen soll, sind redundante Steuerungsebenen, die lokale Abhängigkeiten in jedem Rechenzentrum (AD, DNS, SQL, Hypervisor usw.) verwenden, angemessener. Wenn der Kunde global ist und mehrere Rechenzentren für die Wartung von Citrix mit entsprechenden lokalen Anwendungs-Backends in diesen Rechenzentren einsetzt (oder dies plant), ist es wahrscheinlicher, dass eine geolokalisierte Active-Active HA-DR-Architektur besser geeignet ist. Diese Architektur bietet Benutzern die optimale Benutzererfahrung, wenn möglich, indem geolokalisierte Citrix-Infrastrukturen verwendet werden, die bei Bedarf in einer sekundären Präferenzreihenfolge an ein Backup-Rechenzentrum übergeben werden können.
- Clientbenutzer.Neben民主党obigen Punkt uber Uberlegungen苏珥Benutzer-, App- und Datenlokalisierung können einige Client-Benutzernetzwerke relativ mit Sicherheitsgeräten (Proxy, Firewall usw.) gesperrt werden, die ausgehende Kommunikation mit dem Internet oder sogar dem WAN einschränken können. Es ist wichtig zu prüfen, ob dieser Status für die Client-Netzwerke gilt, und sicherzustellen, dass neue IPs für Citrix IPs (wie StoreFront VIP- und VDA-IPs oder Citrix Gateway IP) in ihren lokalen Sicherheitskonfigurationen berücksichtigt werden, um sicherzustellen, dass keine weiteren Verzögerungen bei der Wiederherstellung aufgrund der lokalen LAN-Sicherheit auftreten Einschränkungen beim Aufrufen von DR. Wird sich der Kundenzugang aus Sicht der Bereitschaft im Falle einer DR auf irgendeine Weise ändern? In einigen DR-Szenarien kann ein Kunde davon ausgehen, dass das WAN nicht verfügbar ist und alle Benutzer über das Internet auf Citrix-Ressourcen zugreifen müssen. Für solche Schritte wären eine Dokumentation im BC und Bereitschaftspläne erforderlich, mit Voraussetzungen für Endbenutzer (in Bezug auf unterstützte Citrix Clientdetails, Annahmen für den Zugriff auf Unternehmens- oder BYOD-Geräte), um Hindernisse für Benutzer zu beseitigen, die an den Service zurückkehren, wodurch die Belastung des Supportpults weiter reduziert wird.
- Netzwerkbandbreite.Die Menge der Netzwerkbandbreite, die in Bezug auf den VDA-Verkehr (ICA, Anwendungen, File-Services) verwendet wird, muss in die Dimensionierung und Firewalls des DR-Einrichtungsnetzwerks einbezogen werden. Diese Überlegung ist besonders wichtig in Cloud-Umgebungen, in denen Beschränkungen für VPN-Gateways und virtuelle Firewall-Kapazitäten bestehen. Die Überwachung des Produktionsdatenverkehrs von VDAs zur Ermittlung eines Durchschnittswerts für die Dimensionierung ist wichtig, um das Netzwerk effektiv zu dimensionieren Wenn Netzwerkeinschränkungen bestehen, müssen Unternehmen unterschiedliche Netzwerkkonfigurationen verwenden, um die erwartete DR-Verkehrslast zu berücksichtigen, wenn und wenn sie aufgerufen werden. Die WAN-Optimierungstechnologie von Citrix SD-WAN kann dazu beitragen, die Datenverkehrsanforderungen zu reduzieren.
- Fallback (oder Failback).Benutzerdaten,要是死在der geandert博士哈西奇ben, oder wenn sich VDA-Images während der DR in der DR geändert haben, muss die Organisation ein Failback planen, um diese Änderungen wieder auf die Produktion zu übertragen, ist die Produktionsumgebung als wiederherstellbar. Für Benutzerdaten kann es so einfach sein wie die Umkehrung der Replikationsreihenfolge und die Wiederherstellung; in ähnlicher Weise für die Citrix Infrastruktur, wenn keine einzelnen Image-Management-Technologien verwendet werden. Bei Verwendung von MCS oder PVS können Masterimages oder vDisks manuell auf die Produktion zurückgeführt und VDAs entsprechend aktualisiert werden.

In der folgenden Liste werden verschiedene allgemeine Wiederherstellungsoptionen für Citrix beschrieben. Anpassungen von jedem existieren auf dem Gebiet, aber zum Vergleich skizzieren wir grundlegende Versionen von jedem. Die Optionen sind beginnend mit den einfachsten (oft höheren RTO und niedrigeren Kosten) durch die fortgeschritteneren (oft niedrigeren RTO, aber höhere Kosten) organisiert. Die ideale Option für eine bestimmte Organisation besteht darin, sich zusätzlich zu den verfügbaren IT-Fähigkeiten, dem Budget und der Infrastruktur an die Wiederherstellungszeit für gehostete Anwendungen oder Anwendungsfälle anzupassen. Obwohl dies möglich ist, weisen viele Optionen darauf hin, dass in Netzwerk und Speicher integrierte Citrix-Technologien wie ADC- und Single-Image-Management-Technologien nicht für andere Methoden als “Always on” Recovery-Modelle geeignet sind. Es ist nicht so, dass es technisch unmöglich wäre, dies zu erreichen, aber die Komplexität, die mit ihrer Erreichung verbunden ist, kann die Erholung riskanter und anfälliger für menschliche Fehler machen.
Wiederherstellungsoption - Wiederherstellen von Offline-Backup

Vor- und Nachteile
Vorteile:
- Niedrigere Wartungskosten verglichen mit Replikations- oder Hot-Standby-Lösungen
Nachteile:
- Hohe Auswirkungen auf Ausfallzeiten
- Umfassende, detailliertere Dokumentation des Wiederherstellungsplans (DR Orchestration)
- Verlängerte Erholungszeit
- Verlässt sich auf Integrität und Alter der Backups
- Höherer Grad an menschlichem Versagen, wenn eine manuelle Rekonfiguration erforderlich ist (Vernetzung usw.)
- 不geeignet毛皮集中、快速克隆MCS奥得河pv
- Aufgrund von Netzwerken nicht für Citrix VPX ADC geeignet (und muss möglicherweise mit Backups der Dateien im Verzeichnis
nsconfigundns.conf-Dateien neu erstellt werden)
Anwendungsfall und Annahmen
Nützlich für weniger ausgereifte IT-Organisationen und Organisationen mit begrenzten IT-Betriebsbudgets und kann längere Ausfälle zur Wiederherstellung der wichtigsten Geschäftsservices ermöglichen. Geht davon aus, dass Backups regelmäßig auf Wiederherstellungsintegrität getestet werden und eindeutig dokumentierte Wiederherstellungsprozesse
Wiederherstellungsoption — Wiederherstellung über Replikation

Vor- und Nachteile
Vorteile:
- Die Replikation ist wahrscheinlich automatisiert und richtet sich nach RTO und RPOs
- Verwendet wahrscheinlich weniger komplexe Technologien im Vergleich zu automatisierten Wiederherstellungslösungen
Nachteile:
- Verlässt sich auf administrative Eingriffe
- Umfassende, detailliertere Dokumentation des Wiederherstellungsplans (DR Orchestration)
- Höherer Grad an menschlichem Versagen, wenn eine manuelle Rekonfiguration erforderlich ist (Vernetzung usw.)
- 不geeignet毛皮集中、快速克隆MCS奥得河pv. Recreation of Machine Catalogs wird in den projizierten RTO einbezogen. Durch das Erstellen von Dummy-Maschinenkatalogen in DR oder das Ausskalieren von VDA-Instanzen in der DR und das Ausführen einer Aktion “Katalog aktualisieren” beim Anwenden eines replizierten Masterimages kann diese RTO jedoch verkürzt werden
- Aufgrund der Vernetzung nicht für Citrix VPX ADC geeignet und daher besser geeignet für den Einsatz von Hot-Standby-ADC
Anwendungsfall und Annahmen
Nützlich für weniger ausgereifte IT-Organisationen und Organisationen mit begrenzten IT-Betriebsbudgets. Diese Lösung stützt sich auf Speicherreplikationstechnologien des SAN-Anbieters oder Hypervisor-Anbieters (vSphere Replication usw.), um VMs über das WAN auf eine andere Einrichtung zu replizieren.
Wiederherstellungsoption — Replikation mit automatisierter Wiederherstellung

Vor- und Nachteile
Vorteile:
- Niedrigere Wartungskosten im Vergleich zu Hot-Standby-Lösungen
- Die Replikation ist wahrscheinlich automatisiert und richtet sich nach RTO und RPOs
- Wiederherstellungspläne sind in der Regel automatisiert
- Weniger administrative Eingriffe und menschliches Versagen
Nachteile:
- Verlassen Sie sich auf fortschrittlichere Technologien wie VMware SRM, Veeam, Zerto, ASR zur Orchestrierung der Recovery und zur Änderung von Netzwerkparametern
- 不geeignet毛皮集中、快速克隆MCS奥得河pv. Recreation von Maschinenkatalogen muss in den projizierten RTO einbezogen werden. Durch das Erstellen von Dummy-Maschinenkatalogen in DR oder das Ausskalieren von VDA-Instanzen in der DR und das Ausführen einer Aktion “Katalog aktualisieren” beim Anwenden eines replizierten Masterimages kann diese RTO jedoch verkürzt werden
- Aufgrund der Vernetzung nicht für Citrix VPX ADC geeignet und daher besser geeignet für den Einsatz von Hot-Standby-ADC
Anwendungsfall und Annahmen
Nützlich für Unternehmensorganisationen mit angemessenen Ressourcen und Budget für die DR-Einrichtung. Diese Lösung basiert auf der gleichen Speicherreplikation der vorherigen Option, enthält jedoch DR-Orchestrationstechnologien, um VMs in bestimmter Reihenfolge wiederherzustellen, NIC-Konfigurationen anzupassen (falls erforderlich) und so weiter
Wiederherstellungsoption — Hot-Standby (Aktiv-Passiv) mit manuellem Failover

Vor- und Nachteile
Vorteile:
- Kurze Wiederherstellungszeit, da die Plattform “immer aktiv” ist
- Unterstützt speicher- und netzwerkabhängige Komponenten wie VPX, MCS, PVS
- Dokumentation des niedrigeren Wiederherstellungsplans (DR-Orchestrierung)
Nachteile:
- Verlässt sich auf administrative Eingriffe, um ein Failover der URL durchzuführen oder Benutzer zur Backup-URL zu leiten
- Höhere Kosten durch “heiße” Hardware in DR im Standby-Modus
- Höherer Verwaltungsaufwand, um die Konfigurationen und Updates der Standby-Plattform mit der Produktion synchron
Anwendungsfall und Annahmen
Nützlich für Unternehmensorganisationen mit angemessenen Ressourcen und Budget für die DR-Einrichtung. Kann eine “vollständig skalierte” Plattform im Hot-Standby oder eine “Scale On-Demand” -Plattform verwenden. Letzteres kann für die Cloud-Wiederherstellung attraktiv sein, um die Betriebskosten zu senken, mitVorbehalten.
Zum Zeitpunkt der Failover-Administratoren aktualisieren die**DNS-Einträge** für eine oder mehrere Zugriffs-URLs, die auf eine oder mehrere DR-IPs für Citrix Gateway und StoreFront verweisen, oder Benutzer werden von der formellen Kommunikation darauf hingewiesen, mit der Verwendung einer “Backup” oder “DR” -URL zu beginnen.
Diese manuelle Option kann für Szenarien nützlich sein, in denen Anwendungs-Back-Ends eine längere Wiederherstellungszeit erfordern können, aber für Benutzer Verwirrung stiften, wenn Citrix vollständig verfügbar wäre und Anwendungen nicht verfügbar wären.
Dieses Modell geht von einer ausgereiften IT-Organisation aus, und es stehen genügend WAN- und Computing-Infrastrukturen zur Verfügung, um Failover zu unterstützen.
Wiederherstellungsoption — Hot-Standby (Aktiv-Passiv) mit automatisiertem Failover

Vor- und Nachteile
Vorteile:
- Kurze Wiederherstellungszeit, da die Plattform “immer aktiv” ist
- Unterstützt speicher- und netzwerkabhängige Komponenten wie VPX, MCS, PVS
- Dokumentation des minimalen Wiederherstellungsplans (DR-Orchestrierung)
- Einfacher für Endbenutzer als URLs Failover
- Unterstützt EPA-Scans bei Citrix Gateway
Nachteile:
- Höhere Kosten durch “heiße” Hardware in DR im Standby-Modus und Citrix ADC Lizenzierung
- Höhere Komplexität der Zugangsebene
- Höherer Verwaltungsaufwand, um die Konfigurationen und Updates der Standby-Plattform mit der Produktion synchron
Anwendungsfall und Annahmen
明信片gemeinsame Konfiguration麻省理工学院Unternehmenskunden und ermöglicht ein automatisches Failover zum DR-Standort über Citrix ADC GSLB (ADC Advanced oder höher erforderlich). Dieses Modell geht von einer ausgereiften IT-Organisation und einem ausreichenden WAN aus und berechnet eine Infrastruktur, um Failover zu unterstützen. Dieses Modell geht auch davon aus, dass Anwendungs- und Benutzerdatenabhängigkeiten mit den neuesten Versionen/Aktualisierungen von Active Site abgestimmt sind und in der DR-Einrichtung in ähnlicher automatisierter Weise wiederhergestellt werden können, um die verlängerten Auswirkungen des Service auf den Endbenutzer und die Verwirrung aufgrund der Teillösungsfunktionalität zu verringern.
Wiederherstellungsoption — Aktiv-Aktiv mit automatisiertem Failover

Vor- und Nachteile
Vorteile:
- Kurze Wiederherstellungszeit, da die Plattform “immer aktiv” ist
- Unterstützt speicher- und netzwerkabhängige Komponenten wie VPX, MCS, PVS
- Dokumentation des minimalen Wiederherstellungsplans (DR-Orchestrierung)
- Nahtlos für Endbenutzer
Nachteile:
- Höhere Kosten durch “heiße” Hardware in DR im Standby-Modus und Citrix ADC Lizenzierung
- Höchste Komplexität der Zugangsebene
- Höherer Verwaltungsaufwand, um die Konfigurationen und Updates der Standby-Plattform mit der Produktion synchron
- Aktiv/Aktiv GSLB unterstützt derzeit keine EPA-Scans auf Citrix Gateway, Aktiv/Passive GSLB-Konfiguration für Citrix Gateway-URL empfohlen
- Verlässt sich darauf, dass Administratoren die Ressourcen- und Hardwarekapazität in allen Rechenzentren überwachen und anpassen, um sicherzustellen, dass bei wachsender Plattform die Integrität der DR-Kapazität nicht beeinträchtigt wird
Anwendungsfall und Annahmen
明信片erweiterte,河口gangige Konfiguration贝联合国ternehmenskunden und ermöglicht den aktiv-aktiven Betrieb von URLs der Zugriffsebene über Citrix ADC GSLB (ADC Advanced oder höher erforderlich). Diese Funktionalität ist nützlich in Umgebungen mit der Nähe des lokalen Rechenzentrums zueinander oder in Situationen, in denen Rechenzentren entfernt sein können, jedoch mit der Möglichkeit, Benutzer für Szenarien mit mehreren Standorten an bevorzugte Rechenzentren anzuheften (häufig von erweiterten StoreFront-Konfigurationen und GSLB in geringerem Maße).
Dieses Modell geht von einer ausgereiften IT-Organisation und einem ausreichenden WAN aus und berechnet eine Infrastruktur, um Failover zu unterstützen. Dieses Modell geht auch davon aus, dass die Abhängigkeiten von Anwendungs- und Benutzerdaten mit den neuesten Standortversionen/-aktualisierungen abgestimmt sind und in der DR-Einrichtung auf ähnlich automatisierte Weise wiederhergestellt werden können, um die verlängerten Auswirkungen des Service auf den Endbenutzer und die Verwirrung aufgrund der Funktionalität der partiellen Lösung zu verringern.
Notfallwiederherstellung in Public Cloud
Disaster Recovery, die On-Prem to Cloud-Plattformen oder Cloud-to-Cloud umfasst, bringt ihre eigenen Herausforderungen oder Überlegungen mit sich, die sich in lokalen Wiederherstellungsszenarien häufig nicht stellen.
Die folgenden wichtigen Überlegungen können während der DR-Entwurfsplanung berücksichtigt werden, um Fehltritte zu vermeiden, die den DR-Plan, der Cloud-Infrastruktur anwendet, entweder ungültig, kostengünstig oder nicht in der Lage ist, die Zielkapazität im Falle von DR.
Überlegung — Netzwerkdurchsatz
Wirkungsbereiche
Verfügbarkeit, Leistung Kosten
Details
Kunden können die Durchsatz-Juncture-Punkte in ihrer Cloud-Lösung unterschätzen und damit unterdimensionieren, einschließlich virtueller Firewall, VPN-Gateway und WAN-Uplink (AWS Direct Connect, Azure Express Route, GCP Cloud Interconnect usw.), wenn die Citrix Plattform in der Cloud wiederhergestellt und über die WAN. Azure VPN Gateways und AWS Transit Gateways haben derzeit maximale Limits von 1,25 Gbit/s. Dieses Limit kann die Skalierung von Gateways oder die Verwendung mehrerer VPCs (wenn es eine AWS gibt) erfordern, wenn diese für die Cloud-Architektur von entscheidender Bedeutung sind. Viele virtuelle Firewalls haben Lizenzbeschränkungen für den Durchsatz, den sie verarbeiten können, oder für Höchstwerte, selbst bei ihrer höchsten Grenze. Diese Einschränkung kann eine Skalierung der Anzahl der Firewalls und deren Lastenausgleich in irgendeiner Weise erfordern.
Empfehlungen
Gehen Sie beim Erstellen von Berechnungen zur Durchsatzgröße von der vollen DR-Kapazitätslast aus Erfassen Sie die folgenden Daten pro gleichzeitigem Benutzer:
- Geschätzte Bandbreite für ICA
- Geschätzte Anwendungskommunikationsbandbreite pro Sitzung, wenn sie Sicherheitsgrenzen überschreiten
- Geschätzte Bandbreite für Dateidienste pro Sitzung, wenn sie Sicherheitsgrenzen überschreiten
Für die oben genannten Metriken kann es sinnvoll sein, Daten zu aktuellen Verkehrsmustern zu und von VDAs in der Produktion zu sammeln. Es ist auch wichtig zu berücksichtigen, welche anderen Datenflüsse, die nichts mit Citrix zu tun haben, diese Netzwerkpfade voraussichtlich ebenfalls verwenden. Stellen Sie sicher, dass Sie die Netzwerk- und Sicherheitsteams bei der Planung von Citrix DR in Verbindung bringen, um sicherzustellen, dass alle Bandbreitenschätzungen, die Sicherheitszonen und Netzwerksegmente durchlaufen, verstanden und berücksichtigt werden können. Wenn die Bandbreite knapp ist, kann Citrix SD-WAN Optimization dazu beitragen, den Sitzungsfußabdruck auf dem Draht zu senken oder die Bandbreite über mehrere Netzwerkverbindungen zu aggregieren.
Überlegung — Lizenzierung für Windows Desktop OS
Wirkungsbereiche
这些
Details
Es gibt potenziell komplexe Lizenzierungsüberlegungen für Microsoft Desktopbetriebssysteminstanzen, die auf verschiedenen Cloud-Plattformen ausgeführt werden. Microsoft hatseine Cloud-Lizenzrechte im August 2019 überarbeitet, was sich in einigen Bereitstellungsszenarien auf die Auswirkungen auf die VDI-Kosten auswirken kann.
Empfehlungen
Beziehen Sie sich auf die aktuellsten Microsoft-Leitlinien bei der Bestimmung der Anwendungsfallarchitektur Wenn es eine potenzielle Kostenherausforderung für VDI in der DR-Lösung gibt, erwägen Sie eine Ergänzung mit Hosted Shared Desktops (eine Erweiterung von RDS-CALs kann erforderlich sein), falls dies möglich ist, da sie eine größere Flexibilität bei niedrigeren Betriebskosten bieten können.
Überlegung — Timing des VDA-Scale-outs (vor oder während der DR)
Wirkungsbereiche
这些Verfügbarkeit
Details
Kunden fühlen sich von der Cloud angezogen, weil sie Kapazität nur dann bezahlen, wenn sie benötigt wird. Diese Lösung kann die DR-Kosten drastisch senken, indem sie nicht für die reservierte Infrastruktur bezahlt, unabhängig davon, ob sie verwendet wird oder nicht.
In großem Maßstab kann sich ein Cloud-Anbieter jedoch nicht zu einer SLA verpflichten, die Hunderte oder Tausende von VMs gleichzeitig einschaltet. Diese Lösung wird besonders schwierig, wenn der VDA-Footprint für DR voraussichtlich auf Hunderte oder Tausende von Instanzen läuft. Cloud-Anbieter tendieren dazu, die Massenkapazität für verschiedene Instanz-Größen zu erhalten. Dieser Anbieter kann jedoch von Moment zu Moment variieren. Wenn eine Katastrophe auftritt, die ein geografisches Gebiet betrifft, kann es zu Streitigkeiten anderer Mandanten kommen, die auch On-Demand-Kapazität anfordern.
Schlüsselfragen, die beantwortet werden müssen und die Entscheidungen beeinflussen können:
- Ist immer 100% DR-Kapazität erforderlich?
- Müssen wir nur kritische Workloads hosten (d. h. nur eine Teilmenge der Produktion)?
- Ist es möglich, zur Zeit von DR zu skalieren? Falls ja, wurden die Anwendungsfälle von DR Tiers priorisiert, um die unterschiedlichen RTOs der einzelnen Anwendungsfälle besser zu verstehen und ein schrittweises Scale-out der Kapazität zu unterstützen?
- Können wir die Betriebssysteminstanzen, die Anwendungsfälle für Apps oder gehostete gemeinsam genutzte Desktops unterstützen, skalieren, um Bereitstellungszeit zu sparen, und diese Instanzen ausschalten, um Betriebskosten zu sparen?
Empfehlungen
Citrix empfiehlt,西奇zunachst麻省理工学院Ihrem Cloud-Anbieter in Verbindung zu setzen, um festzustellen, ob die erwartete Kapazität innerhalb des RTO-Zeitrahmens eingeschaltet werden kann und ob sie mit On-Demand-Instanzen erfüllt werden kann oder nicht. Um sich gegen Kapazitätsverfügbarkeitsbeschränkungen für VDAs in einem DR-Szenario abzusichern, empfiehlt Citrix die Provisioning von VDAs in so vielen Verfügbarkeitszonen wie möglich. In großem Maßstab kann es sich lohnen, in verschiedenen Cloud-Regionen bereitzustellen und die Architektur entsprechend anzupassen. Einige Cloud-Anbieter haben vorgeschlagen, unterschiedliche Größen von VM-Instanztypen zu verwenden, um die VM-Erschöpfung weiter zu verringern. Wenn möglich, wäre es ratsam, VDA-Instanzen vorab bereitzustellen und sie offline zu lassen und sie regelmäßig zu aktualisieren. Die Bereitstellung ist ein ressourcen- und zeitintensiver Prozess, und die bedarfsorientierte Skalierung der VDA-DR-Kapazität kann durch Pre-Provisioning bis zu einem gewissen Grad beschleunigt werden. Wenn das Unternehmen wenig Appetit auf Kapazitätsverfügbarkeitsrisiken hat, kann es erforderlich sein, reservierte oder dedizierte Rechenkapazitäten anzuwenden und entsprechend eine Budgetierung zu gewährleisten. Es ist möglich, On-Demand- und Reserved\ dedizierte Modelle zu kombinieren, indem auf die DR-Wiederherstellungsstufe verwiesen wird, bei denen VDAs sofort verfügbar sein müssen, während andere die Flexibilität haben, über einen längeren RTO von mehreren Tagen oder Wochen wiederhergestellt zu werden, wenn sie weniger kritisch für die Aufrechterhaltung der geschäftlich.
Berücksichtigung — Anwendungs- und Benutzerdaten
Wirkungsbereiche
这些, Verfügbarkeit und Leistung
Details
Der Speicherort冯Benutzerdaten Anwendungs-Back-Ends kann sich erheblich auf die Leistung und manchmal auf die Verfügbarkeit der Citrix DR-Umgebung auswirken. Einige Kundenszenarien verwenden einen DR-Ansatz für mehrere Rechenzentren, bei dem nicht alle Anwendungs-Backends oder Benutzerdaten wie Heim- und Abteilungslaufwerke nicht neben Citrix in der Cloud wiederhergestellt werden können. Diese Lücke kann zu unerwarteten Latenzen führen, die sich auf die Leistung oder sogar die Funktionalität der Anwendungen auswirken können. Aus Sicht des Durchsatzes kann diese Lücke die verfügbare Bandbreite der Netzwerk- und Sicherheits-Appliance verstärken.
Empfehlungen
Wenn möglich, sollten Sie Anwendungs- und Benutzerdaten lokal auf der Citrix-Plattform in DR speichern, um die Leistung so optimal wie möglich zu halten, indem Latenz und Bandbreitenanforderungen im gesamten WAN reduziert werden.
Notfallwiederherstellungsplanung für Citrix Cloud
Es gibt mehrere bemerkenswerte Unterschiede zwischen der lokalen oder “traditionellen” Bereitstellung von Citrix Virtual Apps and Desktops (CVAD) im Vergleich zu Von Citrix Cloud bereitgestellte Citrix DaaS zur DR-Planung:
- Citrix verwaltet die meisten Steuerungskomponenten für den Partner/Kunden und entfernt die wesentlichen DR-Anforderungen für die Citrix Site und ihre Komponenten von ihrer Verantwortung.
- Die Bereitstellung einer DR-Umgebung für Citrix Ressourcen erfordert lediglich, dass ein Kunde Citrix Cloud Connectors im Recovery “Resource Location” und optional StoreFront- und Citrix ADCs für Citrix Gateway bereitstellt.
- Die einzigartige Service-Architektur von Citrix Cloud ist geografisch redundant und robust.
- Access Tier DR ist nicht erforderlich, wenn Citrix Workspace und Citrix Gateway Service verwendet werden.
Neben估计值Kernunterschieden erfordern有火线DR-Überlegungen aus früheren Abschnitten weiterhin eine Partner-/Kundenplanung, da sie die Verantwortung für die Citrix VDAs, Benutzerdaten, Anwendungs-Backends und Citrix Access Tier behalten, wenn Citrix Gateway Service und Citrix Workspace Service nicht von Citrix Cloud verwendet werden.
In diesem Abschnitt werden wichtige Themen behandelt, die Kunden bei der Definition einer geeigneten DR-Strategie für Citrix Cloud unterstützen.
Citrix DaaS vereinfacht Disaster Recovery
Im Folgenden finden Sie ein typisches Konzeptdiagramm, das die konzeptionelle Architektur von Citrix DaaS beschreibt, zusätzlich zur Trennung der Verantwortlichkeiten für von Citrix verwaltete Komponenten und von Partnern und Kunden verwaltete Komponenten. Hier nicht dargestellt sind die WEM-, Analytics- und Citrix Gateway- “Dienste”, bei denen es sich um Wahlkomponenten von Citrix Cloud handelt, die sich auf Citrix DaaS beziehen und unter “Managed by Citrix” fallen würden.

Wie in der Abbildung dargestellt, fällt ein erheblicher Teil der Control-Komponenten, für die Wiederherstellungsentscheidungen erforderlich sind, in den Managementbereich von Citrix. Als Cloud-basierter Dienst ist die Citrix DaaS-Architektur innerhalb derCitrix Cloud-Regionäußerst widerstandsfähig. Es ist Teil der “Secret Sauce” von Citrix Cloud und wird in denSLAs von Citrix Cloudberücksichtigt.
Die Verantwortlichkeiten für das Service-Verfügbarkeitsmanagement lauten wie
- Citrix ist.Control Plane und Zugriff auf “Dienste” bei Verwendung (Workspace, Citrix Gateway Service).
- Kunde.Ressourcenstandortkomponenten wie Cloud Connectors, VDAs, Anwendungs-Backends, Infrastrukturabhängigkeiten (AD, DNS usw.) und Zugriffsstufe (StoreFront, Citrix ADCs), wenn keine Citrix Cloud-Zugriffsstufe verwendet wird.
Kunden profitieren von folgenden Vorteilen in Bezug auf Disaster Recovery auf Citrix DaaS:
- Geringerer Verwaltungsaufwand durch weniger zu verwaltende Komponenten und weniger unabhängige Konfigurationen, die zwischen den Standorten repliziert und gewartet werden müssen.
- Reduzierte Wahrscheinlichkeit menschlicher Fehler und Konfigurationsdiskrepanzen zwischen Citrix Bereitstellungen aufgrund der zentralisierten Konfiguration der “Citrix Site” in der Cloud.
- Optimierte Abläufe aufgrund der Vereinfachung des Ressourcenmanagements für Produktions- und Disaster Recovery-Bereitstellungen, da weniger Citrix Sites und Komponenten konfiguriert und gewartet werden müssen, keine Zugriffsebene zwischen Standorten (optional) und weniger komplexer Disaster Recovery-Logik für Citrix Ressourcen.
- Reduzierte Betriebskosten mit weniger Serverkomponenten für die Bereitstellung und Wartung und Gewinnung eines einzigen Glasbereichs auf Umgebungstrends in Bereitstellungen hinweg durch die Zentralisierung der Überwachungsdatenbank.
Überlegungen zur Citrix DaaS Disaster Recovery
Obwohl viele Komponenten für die Wiederherstellungsplanung aus dem Managementbereich des Kunden entfernt wurden, bleiben die Kunden für die Planung und Verwaltung von DR und Hochverfügbarkeit (optional) für die Komponenten verantwortlich, die sich innerhalb des Ressourcenstandorts befinden.
Der größte Unterschied in der Art und Weise, wie wir die Verfügbarkeit ansprechen, hängt davon ab, wie wir Ressourcenstandorte interpretieren und konfigurieren. Innerhalb von Citrix DaaS selbst werden Ressourcenstandorte alsZonendargestellt. MitZonenpräferenz能帮我们的故障转移来Ressourcenstandorten basierend auf der von uns angegebenen Logik verwalten. Die Verwendung von Zonenpräferenz in einer traditionell bereitgestellten CVAD-Site würde als Design mit hoher Verfügbarkeit betrachtet, jedoch nicht als gültiges DR-Design. Im Zusammenhang mit Citrix Cloud ist diese Option eine gültige DR-Lösung.
Die meisten der zuvor besprochenenDisaster Recovery-Optionengelten für Citrix DaaS, sodass es zahlreiche Optionen gibt, die den Wiederherstellungszielen und Budgets des Unternehmens entsprechen.
Bei der Planung der DR für den Citrix DaaS-Dienst von Citrix Cloud müssen mehrere wichtige Leitprinzipien aus Sicht der Infrastrukturplanung verstanden werden:
- Resource Standorte.Produktions- und DR-Standorte werden in Citrix Cloud als unabhängige Ressourcenstandorte eingerichtet.
- Cloud-Konnektoren.Für jeden Ressourcenstandort müssen mindestens zwei Cloud Connectors bereitgestellt sein. Zur besseren Übersicht sind Cloud Connectors keine Komponente, die während eines DR-Ereignisses manuell oder automatisch “wiederhergestellt” werden muss. Sie müssen als “Hot-Standby” -Komponenten gelten und an jedem Standort online gehalten werden.
- Von Kunden verwaltete Access Controller (optional).Kunden能帮西奇水平entscheiden,您以头顶Citrix ADCs für Citrix Gateway- und StoreFront-Server bereitzustellen und Citrix Workspace oder Citrix Gateway Service aus mehreren Gründen nicht zu nutzen. Diese können Folgendes umfassen:
- Benutzerdefinierte Authentifizierungsabläufe
- Erweiterte Branding-Fähigkeiten
- Höhere Flexibilität beim Routing von HDX-Datenverkehr
- Prüfung von ICA-Verbindungen und Integration in SIEM-Plattformen
- Möglichkeit, den Betrieb fortzusetzen, wenn die Verbindung des Cloud Connectors zur Citrix Cloud getrennt wird, mithilfe der Local Host Cache-Funktion der Cloud Connectors mit StoreFront
Wie bei den Cloud Connectors wird empfohlen, StoreFront- und Citrix Gateway-Komponenten als “Hot Standby” am Recovery-Standort bereitzustellen und sie während eines DR-Ereignisses nicht wiederherzustellen.
Überlegungen zur Bedienung
Die Aufrechterhaltung der DR-Plattform ist für die Aufrechterhaltung ihrer Integrität unerlässlich, um unvorhergesehene Probleme zu vermeiden, wenn die Plattform benötigt wird. Die folgenden Richtlinien werden für den Betrieb und die Wartung der DR Citrix Umgebung empfohlen:
- Die Citrix DR-Plattform ist nicht ohne Prod.Kunden mit einer “Hot-Standby” -Umgebung können versucht sein, Abstriche zu machen und DR als Testplattform zu behandeln. Diese Behandlung wirkt sich negativ auf die Integrität der Lösung aus. Tatsächlich wäre DR wahrscheinlich die letzte Plattform, auf der Änderungen gefördert wird, um sicherzustellen, dass ihr Nutzen nicht beeinträchtigt wird, wenn die Wartung katastrophal in einer Weise verläuft, die in Nicht-Prod-Umgebungen nicht ausgestellt wurde.
- Patching und Wartung.Routinemäßige Wartung im Schritt zur Produktion bei der Verwendung von “Hot Standby” Citrix Plattformen ist für die Aufrechterhaltung einer funktionalen DR-Plattform unerlässlich. Es ist wichtig, dass DR mit der Produktion in Bezug auf Betriebssystem, Citrix Produkte und Anwendungs-Patches synchron hält. Um das Risiko zu minimieren, wird empfohlen, zwischen der Patch-Produktion und dem Patchen der DR mehrere Tage bis eine Woche einzuplanen.
- Regelmäßige Tests.Unabhängig davon, ob DR die Replikation der Produktion in eine Wiederherstellungseinrichtung oder die Verwendung von “Hot Standby” -Umgebungen beinhaltet, ist es wichtig, den DR-Plan regelmäßig (zweimal im Jahr oder länger ist ideal) zu testen, um sicherzustellen, dass die Teams mit Wiederherstellungsprozessen und etwaigen Fehlern in der Plattform oder den Workflows vertraut sind identifiziert und behoben.
- Kapazitätsmanagement.Zwar sowohl für Active-Passive als auch für Active-Active “Always on” Citrix Umgebungen müssen Kapazitäts- oder Anwendungsfalländerungen in der Produktion auch für DR berücksichtigt werden. Insbesondere wenn Active-Active-Modelle verwendet werden, kann die Ressourcennutzung leicht über beispielsweise einen stationären Auslastungsschwellenwert von 50% in jeder Umgebung hinaus erhöht werden, nur damit ein DR-Ereignis eintritt und die überlebende Plattform überfordert wird und entweder eine schlechte Leistung erbringt oder aufgrund der Überlastung. Die Kapazität kann monatlich oder vierteljährlich überprüft werden.
Zusammenfassung
Wir haben einiges zum Thema Disaster Recovery in Citrix behandelt. In den folgenden Punkten werden die Kernaussagen und Erkenntnisse dieses Handbuchs zusammengefasst, die Architekten und Kunden bei der Planung ihrer Citrix-Wiederherstellungsstrategie berücksichtigen sollten:
- Das Verständnis der geschäftlichen Anforderungen und technologischen Fähigkeiten einer Kundenumgebung beeinflusst die für Citrix erforderliche Disaster Recovery-Strategie. Die gewählte Recovery-Strategie kann sich an die Geschäftsziele anpassen.
- Hochverfügbarkeit ist nicht gleichbedeutend mit Disaster Recovery. Disaster Recovery kann jedoch eine hohe Verfügbarkeit beinhalten.
- Die gemeinsame Nutzung von Verwaltungsgrenzen zwischen physischen Standorten stellt keine Disaster Recovery-Lösung dar.
- Die Entwicklung einer Disaster-Recovery-Tiering-Klassifizierung für das Technologieportfolio eines Unternehmens bietet Transparenz, Flexibilität und potenzielle Kosteneinsparungen bei der Entwicklung einer Wiederherstellungsstrategie.
- Die RTO-Anforderungen für die Citrix Infrastruktur oder die auf Citrix gehosteten Anwendungen sind der wichtigste Einflussfaktor, für den ein Disaster Recovery-Design erforderlich ist. Eine kürzere RTO erfordert oft höhere Lösungskosten.
- Disaster Recovery-Architekturen für Citrix, die keine “heiße” Disaster Recovery-Plattform verwenden, weisen Einschränkungen in Technologien auf, die ein Kunde verwenden kann, wie Citrix MCS, ADC und Provisioning.
- Die Disaster Recovery-Strategie für Citrix muss auch die Recovery- und Recovery-Zeit von Benutzerdaten und Anwendungs-Back-Ends berücksichtigen. Citrix kann so konstruiert werden, dass sie schnell wiederhergestellt werden kann. Benutzer können dennoch nicht arbeiten, wenn Anwendungs- und Datenabhängigkeiten in einem ähnlichen Zeitrahmen nicht verfügbar sind.
- Disaster Recovery in Cloud-Umgebungen verfügt über eigene Überlegungen, die in on-premises Umgebungen nicht vorhanden sind und die Unternehmen überprüfen müssen, um unvorhergesehene Engpässe oder betriebliche Auswirkungen beim Aufrufen von Disaster Recovery in Cloud-Umgebungen zu vermeiden.
- Es ist unerlässlich, dass Disaster Recovery-Komponenten auf dem neuesten Stand gehalten werden, um Produktionsupdates und -konfigurationen zu entsprechen, um die Integrität der Plattform zu erhalten.
- Plattformen, die eine Aktiv-Aktiv-Konfiguration für Citrix zwischen Standorten verwenden, müssen auf die Kapazitätsüberwachung achten, um sicherzustellen, dass im Katastrophenfall ausreichende Ressourcen zur Verfügung stehen, um die prognostizierte Last an einem oder mehreren überlebenden Standorten zu unterstützen.
- Kunden müssen ihren Disaster Recovery-Plan für Citrix regelmäßig testen, um ihren Betrieb und die Fähigkeit, ihren Kernzweck zu erfüllen, zu validieren.
- Citrix DaaS vereinfacht viele Aspekte der DR-Architektur erheblich und ermöglicht die Redundanz des Ressourcenstandorts über die Zonenpräferenzkonfiguration.
Quellen
Das Ziel dieses Artikels ist es, Sie bei der Planung Ihrer eigenen Implementierung zu unterstützen. Um Ihnen diese Aufgabe zu erleichtern, möchten wir Ihnen Quelldiagramme zur Verfügung stellen, die Sie an Ihre eigenen Bedürfnisse anpassen können:Quelldiagramme.
In diesem Artikel
- Übersicht
- Geschäftliche Anforderungen
- Missverstandnisse贝灾难恢复(DR)设计n
- Disaster Recovery (DR) vs. Hochverfügbarkeit (HA)
- Klassifizierung der Disaster Recovery-Stufe
- Optionen für die Notfallwiederherstellung
- Wiederherstellungsoption - Wiederherstellen von Offline-Backup
- Wiederherstellungsoption — Wiederherstellung über Replikation
- Wiederherstellungsoption — Replikation mit automatisierter Wiederherstellung
- Wiederherstellungsoption — Hot-Standby (Aktiv-Passiv) mit manuellem Failover
- Wiederherstellungsoption — Hot-Standby (Aktiv-Passiv) mit automatisiertem Failover
- Wiederherstellungsoption — Aktiv-Aktiv mit automatisiertem Failover
- Notfallwiederherstellung in Public Cloud
- Notfallwiederherstellungsplanung für Citrix Cloud
- Überlegungen zur Bedienung
- Zusammenfassung
- Quellen